install.packages("devtools")
devtools::install_github("hgoers/polisciols")Session 1: Data and Measurement
Learning Objectives
By the end of this module, you should be able to:
Identify different types of measurement scales and their properties
Calculate and interpret measures of central tendency
Calculate and interpret measures of dispersion
Apply these concepts using R statistical software
Set up
Throughout this course, you will need a series of data sets I have collected, cleaned, and stored in the polisciols R package. These data sets were collected and published by political scientists (including some incredible GVPT alumni). This package is not published on CRAN1, so you will need to install it using the following code:
You will also need access to the following R packages to complete this session:
Install packages
To install new R packages, run the following (excluding the packages you have already installed):
install.packages(c("tidyverse", "wbstats", "janitor", "skimr", "countrycode",
"scales"))Why?
You have an interesting question that you want to explore. You have some data that relate to that question. Included in these data are information on your outcome of interest and information on the things that you think determine or shape that outcome. You think that one (or more) of the drivers is particularly important, but no one has yet written about it or proven its importance. Brilliant! What do you do now?
The first step in any empirical analysis is getting to know your data. I mean, really getting to know your data. You want to dig into it with a critical eye. You want to understand any patterns lurking beneath the surface.
Ultimately, you want to get a really good understanding of the data generation process. This process can be thought of in two different and important ways. First, you want to understand how, out there in the real world, your outcome and drivers come to be. For example, if you are interested in voting patterns, you want to know the nitty gritty process of how people actually vote. Do they have to travel long distances, stand in long queues, fill out a lot of paperwork? Are there age restrictions on their ability to vote? Are there more insidious restrictions that might suppress voting for one particular group in the electorate?
You can use the skills we will discuss in this section to help you answer these questions. For example, you can determine whether there are relatively few young voters compared to older voters. If so, why? In turn, your growing expertise in and understanding of the data generation process should inform your exploration of the data. You might note that people have to wait in long queues on a Tuesday to vote. Does this impact the number of workers vs. retirees who vote?
Now, this is made slightly more tricky by the second part of this process. You need to understand how your variables are actually measured. How do we know who turns out to vote? Did you get access to the voter file, which records each individual who voted and some interesting and potentially relevant demographic information about them? Or are you relying on exit polls, that only include a portion of those who voted? Were the people included in the polls reflective of the total voting population? What or whom is missing from this survey? Of course, if your sample is not representative, you might find some patterns that appear to be very important to your outcome of interest but are, in fact, just an artifact of a poorly drawn sample. If your survey failed to get responses from young people, you may be led to falsely believe that young people don’t vote.
This session you will be introduced to the first part of the data analysis process: data exploration. We use descriptive statistics to summarize patterns in our data. These are powerful tools that will inform you of the shape of your variables of interest. With this knowledge, you will start to answer your important question and potentially identify new ones. You will also be able to sense-check your more complex models and pick up on odd or incorrect relationships that they may find.
As you make your frequency tables and histograms and very elaborate dot plots and box charts, keep in mind that these tools are useful for your interrogation of the data generation process. Be critical. Continue to ask whether your data allow you to detect true relationships between your variables of interest. Build your intuition for what is really going on and what factors are really driving your outcome of interest.
Let’s get started.
Describing your data
When conducting quantitative analysis, we need to understand what type of data we’re working with. Different measurement scales allow for different mathematical operations and statistical procedures. As future international relations analysts, recognizing these distinctions will be crucial for properly analyzing global data. Broadly, there are two types of variables: categorical and continuous.
Categorical variables
Categorical variables are discrete. They can be unordered (nominal) or ordered (ordinal).
Nominal variables
Nominal variables classify data into mutually exclusive, unordered categories.
- Properties: Categories with no inherent order
- Examples: Country names, political party affiliation, ethnicity
- Operations allowed: Counting, mode, frequency distributions
- Cannot calculate: Mean, median, standard deviation
In R: Nominal variables are stored as factors.
Ordinal variables
Ordinal scales classify data into categories with a meaningful order, but the intervals between values aren’t necessarily equal.
- Properties: Categories with clear ranking/order
- Examples: Education levels, survey responses (strongly disagree to strongly agree), UN Security Council status
- Operations allowed: All nominal operations plus median, percentiles
- Limited meaning: Mean, standard deviation
In R: Ordinal variables are stored as ordered factors.
Binary variables
Binary variables are a special type of categorical variable. They take on one of two values.
- Properties: Categories with only two levels
- Examples: Voted or not, at war or not, a democracy or not
- Operations allowed: All nominal operations
- Limited meaning: Mean, median, standard deviation
In R: Binary variables are stored as ordered factors.
Continuous variables
Continuous variables are, well, continuous.
- Properties: Variables that can take any value within an interval
- Examples: GDP, population, number of fatalities in a battle
- Operations allowed: Mean, median, standard deviation
- Limited meaning: Counting, mode, frequency distributions
In R: Continuous variables are stored as numeric or integer data types.
gdp <- c(1.6e9, 7e8, 5.8e8, 7.68e8)
gdp[1] 1.60e+09 7.00e+08 5.80e+08 7.68e+08mean(gdp)[1] 9.12e+08Binning
Continuous variables can be made into ordinal variables. This process is called binning. For example, you can take individuals’ ages and reduce them to intervals of 10 years.
ages <- c(23L, 21L, 57L, 24L, 43L, 25L, 71L, 28L, 43L, 56L)
cut_width(ages, width = 10, boundary = 15) [1] [15,25] [15,25] (55,65] [15,25] (35,45] [15,25] (65,75] (25,35] (35,45]
[10] (55,65]
Levels: [15,25] (25,35] (35,45] (45,55] (55,65] (65,75]You lose information in this process: you cannot go from 45 - 65 years old back to the individuals’ precise age. In other words, you cannot go from a categorical to continuous variable.
Describing categorical variables
Let’s take a look at how you can describe these different types of variables using real-world political science examples. Generally, we can get a good sense of a categorical variable by looking at counts or proportions. For example, which category contains the most number of observations? Which contains the least?
Note
Later, we will ask interesting questions using these summaries. These include whether differences between the counts and/or percentages of cases that fall into each category are meaningfully (and/or statistically significantly) different from one another. This deceptively simple question serves as the foundation for a lot of empirical research.
Let’s use the American National Election Survey to explore how to produce useful descriptive statistics for categorical variables using R. The ANES surveys individual US voters prior to and just following US Presidential Elections. It asks them about their political beliefs and behavior.
We can access the latest survey (from the 2020 Presidential Election) using the polisciols package:
polisciols::nes
Exercise
Take a look at the different pieces of information collected about each respondent by running ?nes in your console.
Let’s look at US voters’ views on income inequality in the US. Specifically, we will look at whether individuals think the difference in incomes between rich people and poor people in the United States today is larger, smaller, or about the same as it was 20 years ago.
Respondents could provide one of four answers (or refuse to answer the question, which is marked as NA):
distinct(nes, income_gap)# A tibble: 5 × 1
income_gap
<ord>
1 About the same
2 Larger
3 Smaller
4 <NA>
5 Don't know This is an ordinal variable. It is discrete and has a clear ranking. We can take a look at the variable itself using the helpful skimr::skim() function:
skim(nes$income_gap)| Name | nes$income_gap |
| Number of rows | 8280 |
| Number of columns | 1 |
| _______________________ | |
| Column type frequency: | |
| factor | 1 |
| ________________________ | |
| Group variables | None |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| data | 54 | 0.99 | TRUE | 4 | Lar: 6117, Abo: 1683, Sma: 416, Don: 10 |
From this, we learn that:
- We have information on
nrow(nes) |> comma()observations (or respondents) - The variable type is a factor (see the R tip below)
- We are missing 54 observations (in other words, 54 people did not answer the question)
- This means that we have information on 99% of our observations (from
complete_rate).
Tip
In base R:
summary(nes$income_gap) Don't know Smaller About the same Larger NA's
10 416 1683 6117 54 Frequency distribution
What count and proportion of respondents provided each answer? We can take advantage of janitor::tabyl() to quickly calculate this:
tabyl(nes, income_gap) income_gap n percent valid_percent
Don't know 10 0.001207729 0.001215658
Smaller 416 0.050241546 0.050571359
About the same 1683 0.203260870 0.204595186
Larger 6117 0.738768116 0.743617797
<NA> 54 0.006521739 NA
Tip
valid_percent provides the proportion of respondents who provided each answer with missing values removed from the denominator. For example, the ANES surveyed 8,280 respondents in 2020, but only 8,226 of them answered this question.
6,117 responded that they believe the income gap is larger today than it was 20 years ago. Therefore, the Larger proportion (which is bounded by 0 and 1, whereas percentages are bounded by 0 and 100) is 6,117 / 8,280 and its valid proportion is 6117 / 8,226.
Visualizing this frequency
It is a bit difficult to quickly determine relative counts. Which was the most popular answer? Which was the least? Are these counts very different from each other?
Visualizing your data will give you a much better sense of it. I recommend using a bar chart to show clearly relative counts.
ggplot(nes, aes(y = income_gap)) +
geom_bar() +
theme_minimal() +
labs(
x = "Count of respondents",
y = NULL,
caption = "Source: ANES 2020 Survey"
) +
scale_x_continuous(labels = scales::label_comma())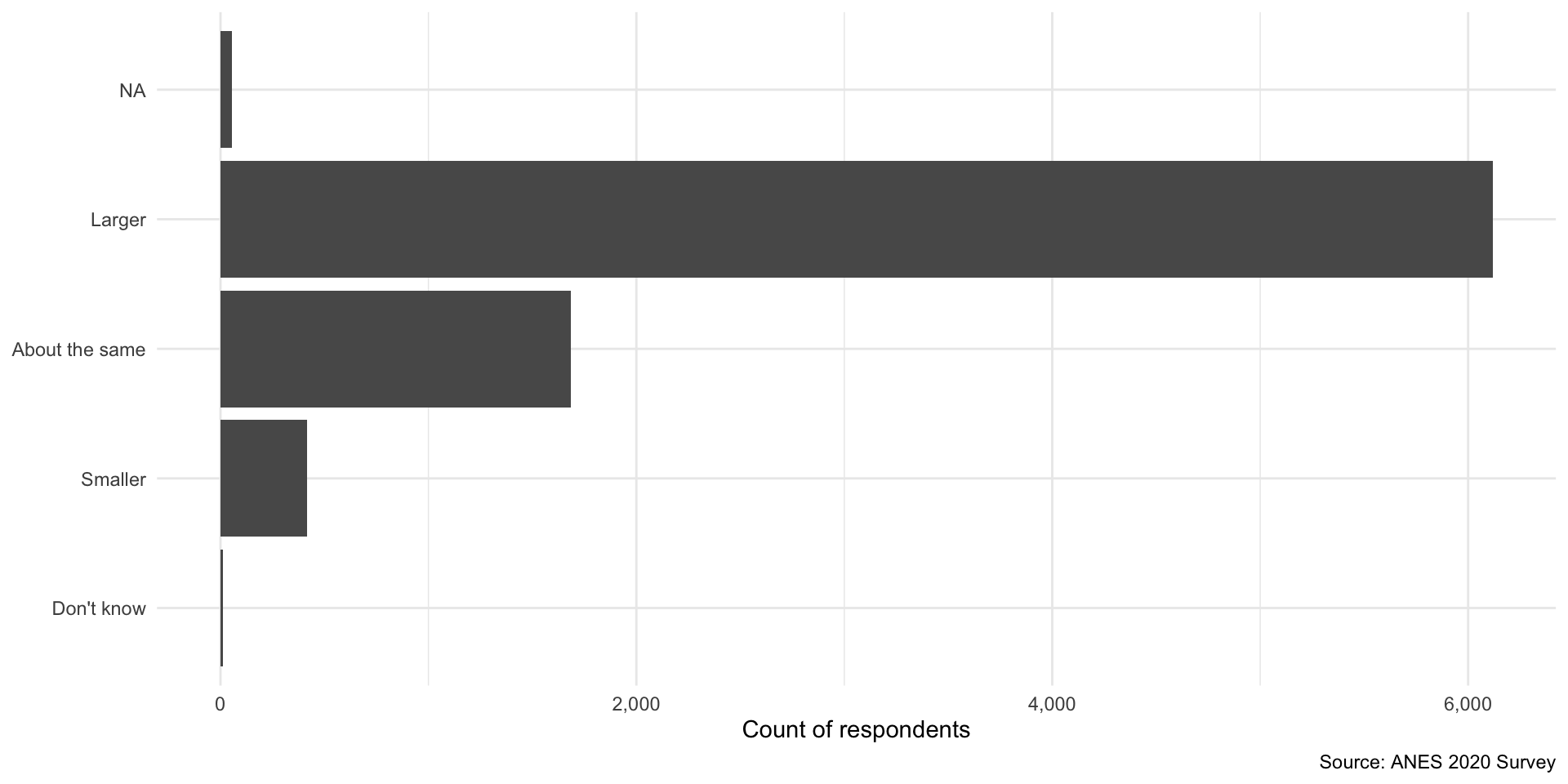
Tip
geom_bar() automatically counts the number of observations in each category.
From this plot we quickly learn that a large majority of respondents believe that the income gap has grown over the last 20 years. Very few people believe it has shrunk.
Describing continuous variables
We need to treat continuous variables differently from categorical ones. Continuous variables cannot meaningfully be bound together and compared. For example, imagine making a frequency table or bar chart that counts the number of countries with each observed GDP. You would have 193 different counts of one. Not very helpful!
We can get a much better sense of our continuous variables by looking at how they are distributed across the range of all possible values they could take on. Phew! Let’s make sense of this using some real-world data.
For this section, we will look at how much each country spends on education as a proportion of its gross domestic product (GDP). We will use wbstats::wb_data() to collect these data directly from the World Bank’s data portal.
perc_edu <- wb_data(
"SE.XPD.TOTL.GD.ZS", start_date = 2020, end_date = 2020, return_wide = F
) |>
transmute(
country,
region = countrycode(country, "country.name", "region"),
year = date,
value
)
perc_edu# A tibble: 217 × 4
country region year value
<chr> <chr> <dbl> <dbl>
1 Afghanistan South Asia 2020 NA
2 Albania Europe & Central Asia 2020 3.34
3 Algeria Middle East & North Africa 2020 6.19
4 American Samoa East Asia & Pacific 2020 NA
5 Andorra Europe & Central Asia 2020 2.63
6 Angola Sub-Saharan Africa 2020 2.67
7 Antigua and Barbuda Latin America & Caribbean 2020 2.99
8 Argentina Latin America & Caribbean 2020 5.28
9 Armenia Europe & Central Asia 2020 2.71
10 Aruba Latin America & Caribbean 2020 NA
# ℹ 207 more rows
Note
I have added each country’s region (using countrycode::countrycode()) so that we can also explore regional trends in our data.
We can get a good sense of how expenditure varied by country by looking at the center, spread, and shape of the distribution.
Visualizing continuous distributions
First, let’s plot each country’s spending to see how they relate to one another. There are two plot types commonly used for this: histograms and density curves.
Histograms
A histogram creates buckets along the range of values our variable can take (i.e. buckets of 10 between 1 and 100 would include 1 - 10, 11 - 20, 21 - 30, etc.). It then counts the number of observations that fall into each of those buckets and plots that count.
Let’s plot our data as a histogram with a bin width of 1 percentage point:
ggplot(perc_edu, aes(x = value)) +
geom_histogram(binwidth = 1) +
theme_minimal() +
labs(
x = "Expenditure on education as a proportion of GDP",
y = "Number of countries"
)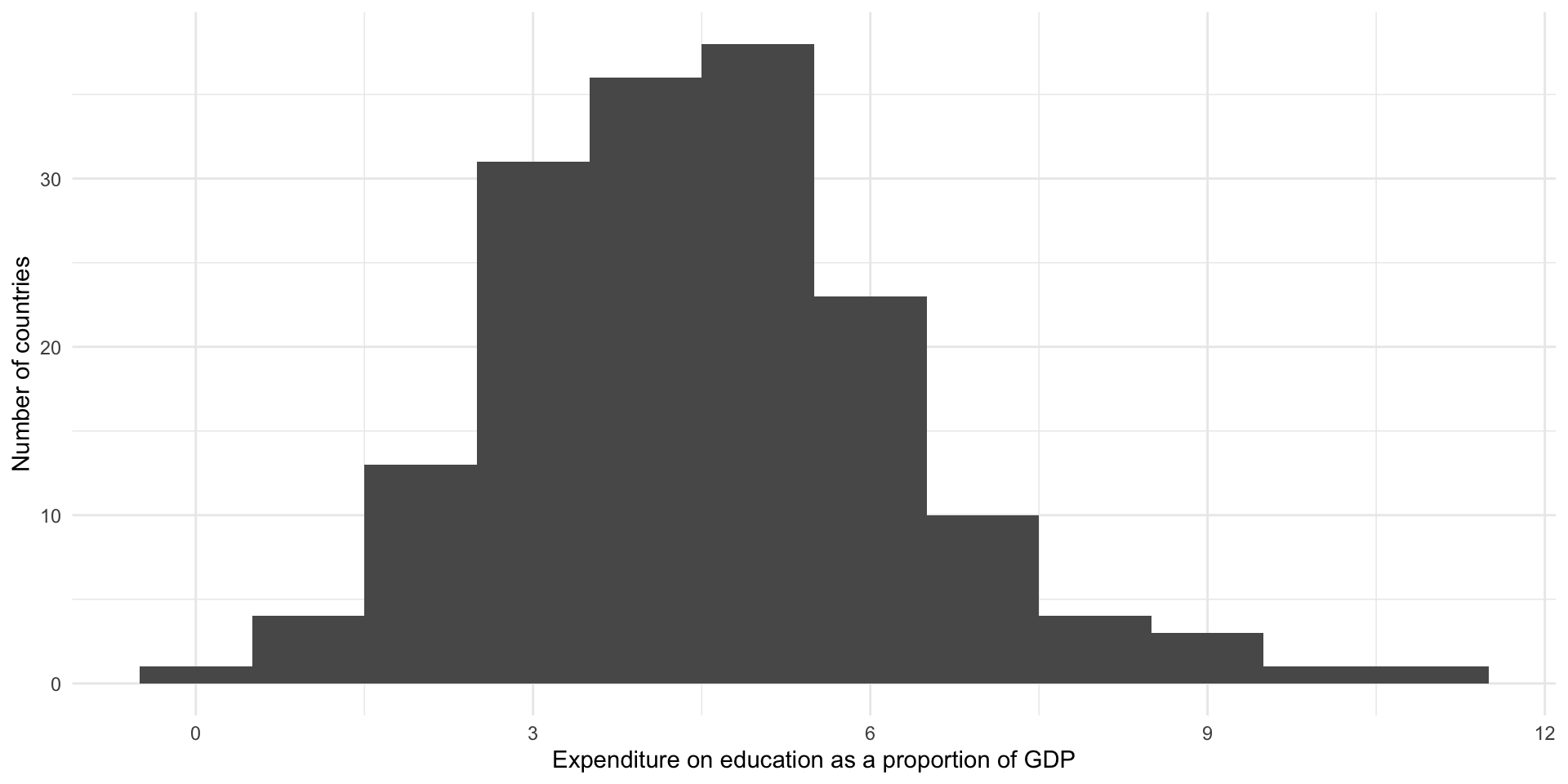
From this we learn that most countries spend between three to five percent of their GDP on education. There appears to be some outliers. Some countries spend over 10 percent of their GDP on education. This is well above the proportion all other countries spent.
If we pick a narrower bin width, we will see more fine-grained detail about the distribution of our data:
ggplot(perc_edu, aes(x = value)) +
geom_histogram(binwidth = 0.25) +
theme_minimal() +
labs(
x = "Expenditure on education as a proportion of GDP",
y = "Number of countries"
)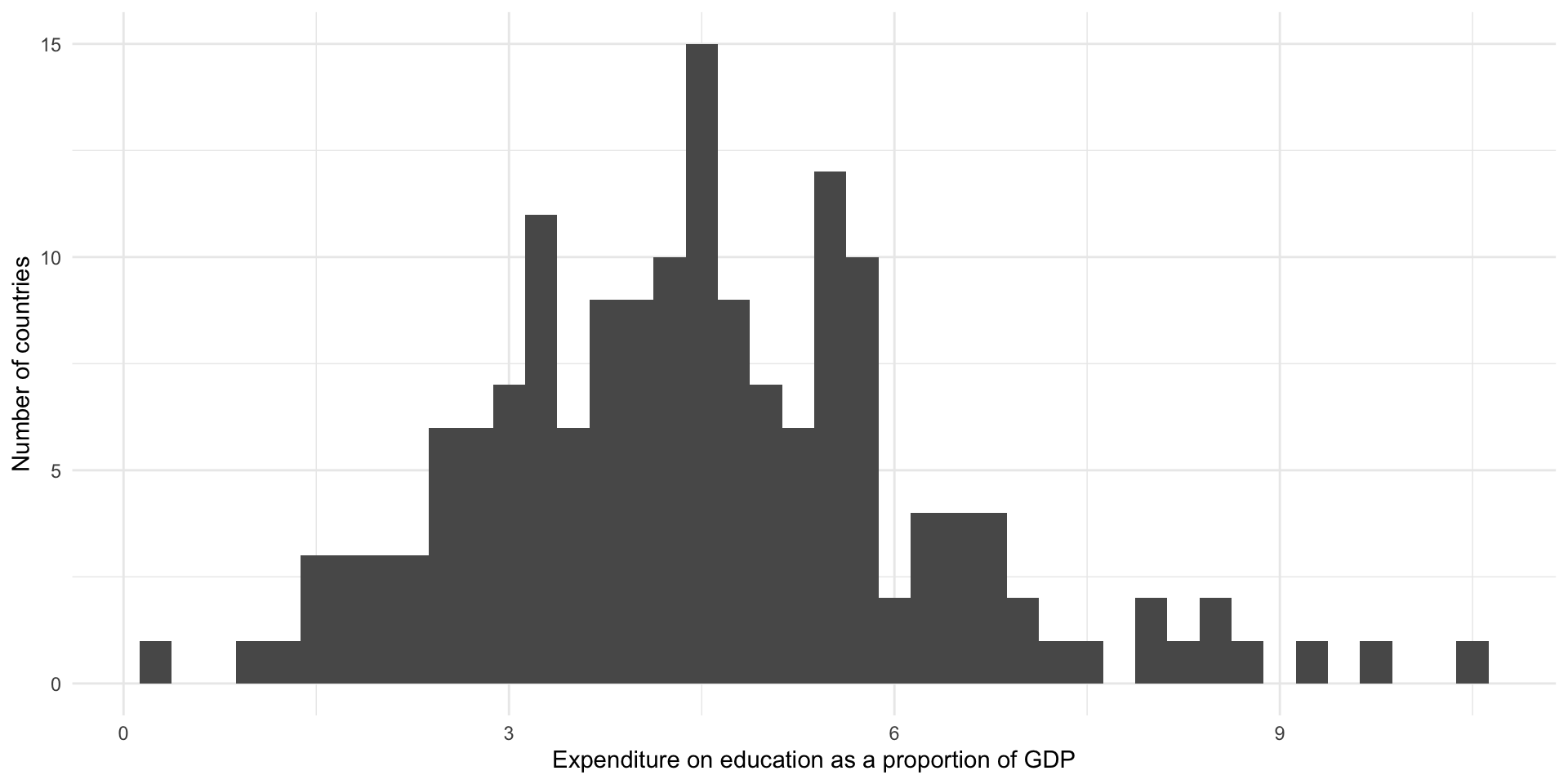
From this we learn that most countries spent around four percent of their GDP on education. There is a small cluster of countries that spent between around 7.5 to nine percent on these services. Three countries spent an unusually large proportion of their GDP (over 10 percent of it) on education annually.
Density curves
Density curves also communicate the distribution of continuous variables. They plot the density of the data that fall at a given value on the x-axis.
Let’s plot our data using a density plot:
ggplot(perc_edu, aes(x = value)) +
geom_density() +
theme_minimal() +
labs(
x = "Expenditure on education as a proportion of GDP",
y = "Density"
)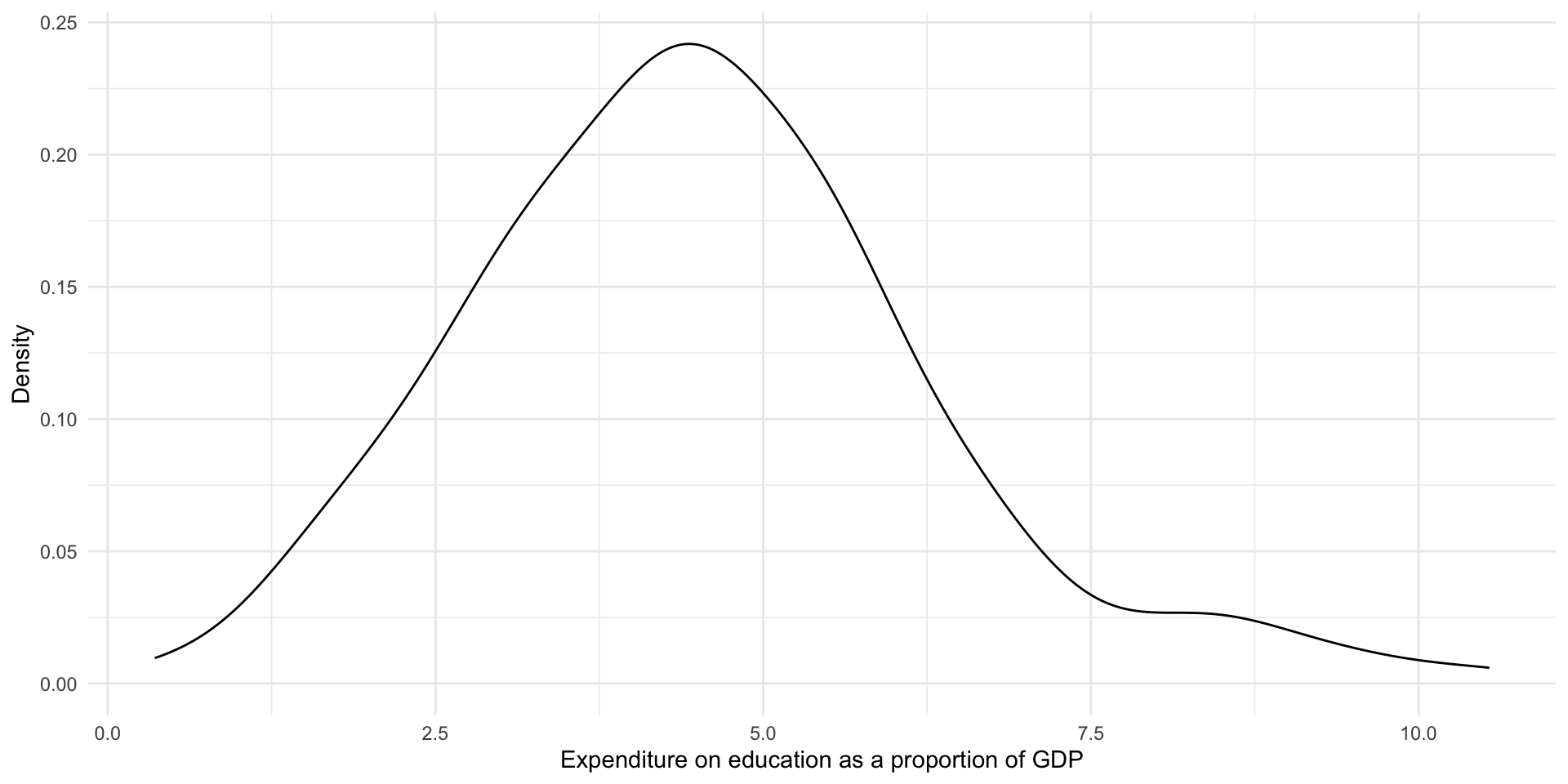
This provides us with the same information above, but highlights the broader shape of our distribution. We again learn that most countries spend around four percent of their GDP on education. There are some that spend above 7.5 percent.
Understanding distributions
We can use the shape of a variable’s distribution to usefully summarize it or to more easily compare it to other variables. Is the distribution symmetric or skewed? Where are the majority of observations clustered? Are there multiple distinct clusters, or high points, in the distribution?
There are three broad distributions that you should know: Normal, right-skewed, and left-skewed. People use these terms to summarize the shape of their continuous data.
Normal distribution
A Normally distributed variable includes values that fall symmetrically away from their center point, which is the peak (or most common value). Examples of Normally distributed data include the height or weight of all individuals in a large population.
Note
This distribution is also referred to as a bell-curve.
ggplot() +
geom_density(aes(x = rnorm(n = 1e6))) +
theme_void()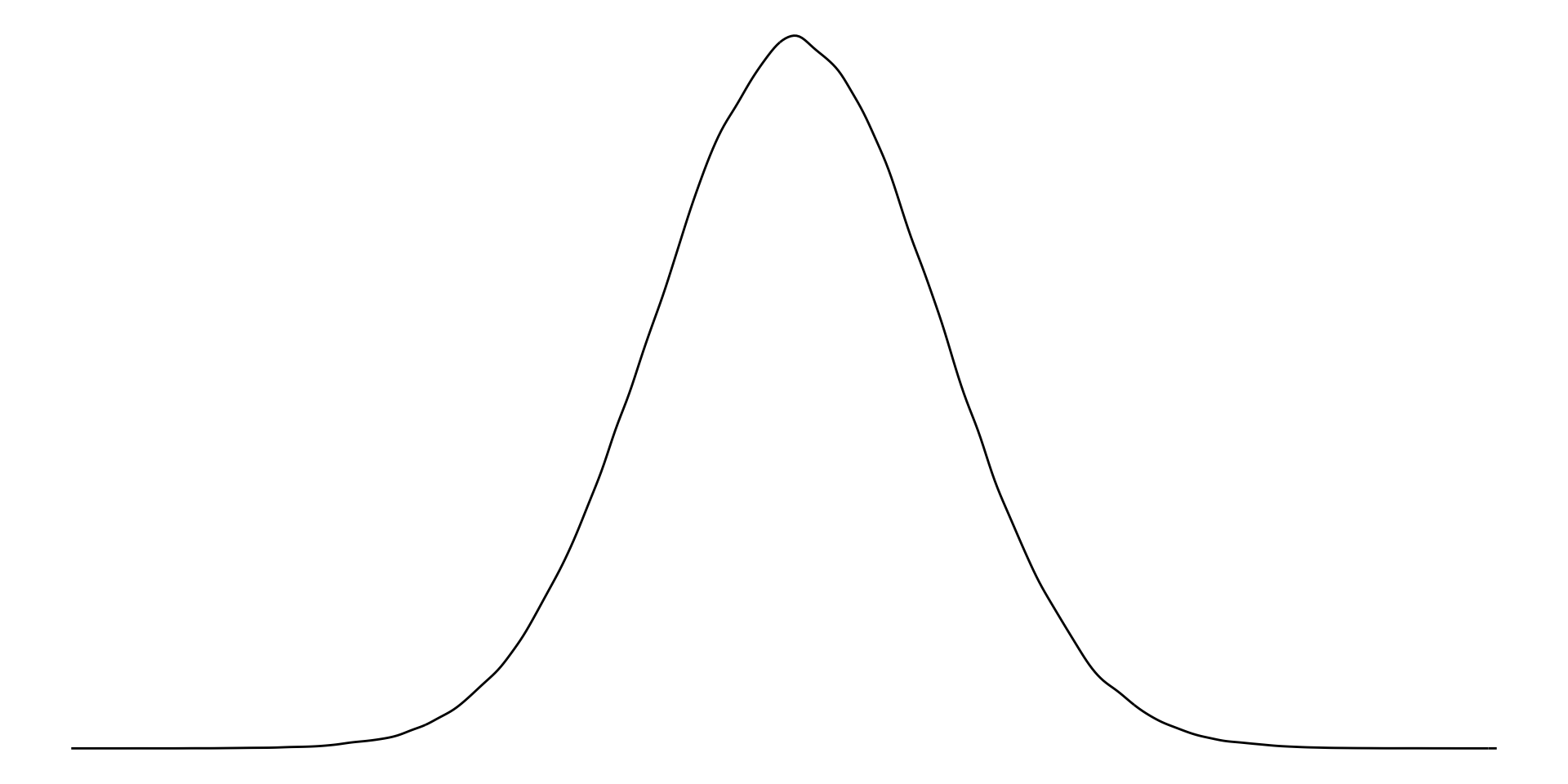
Right-skewed distribution
With right-skewed data, the majority of data have small values with a small number of larger values. Examples of right-skewed data include countries’ GDP.
ggplot() +
geom_density(aes(x = rbeta(1e6, 2, 10))) +
theme_void()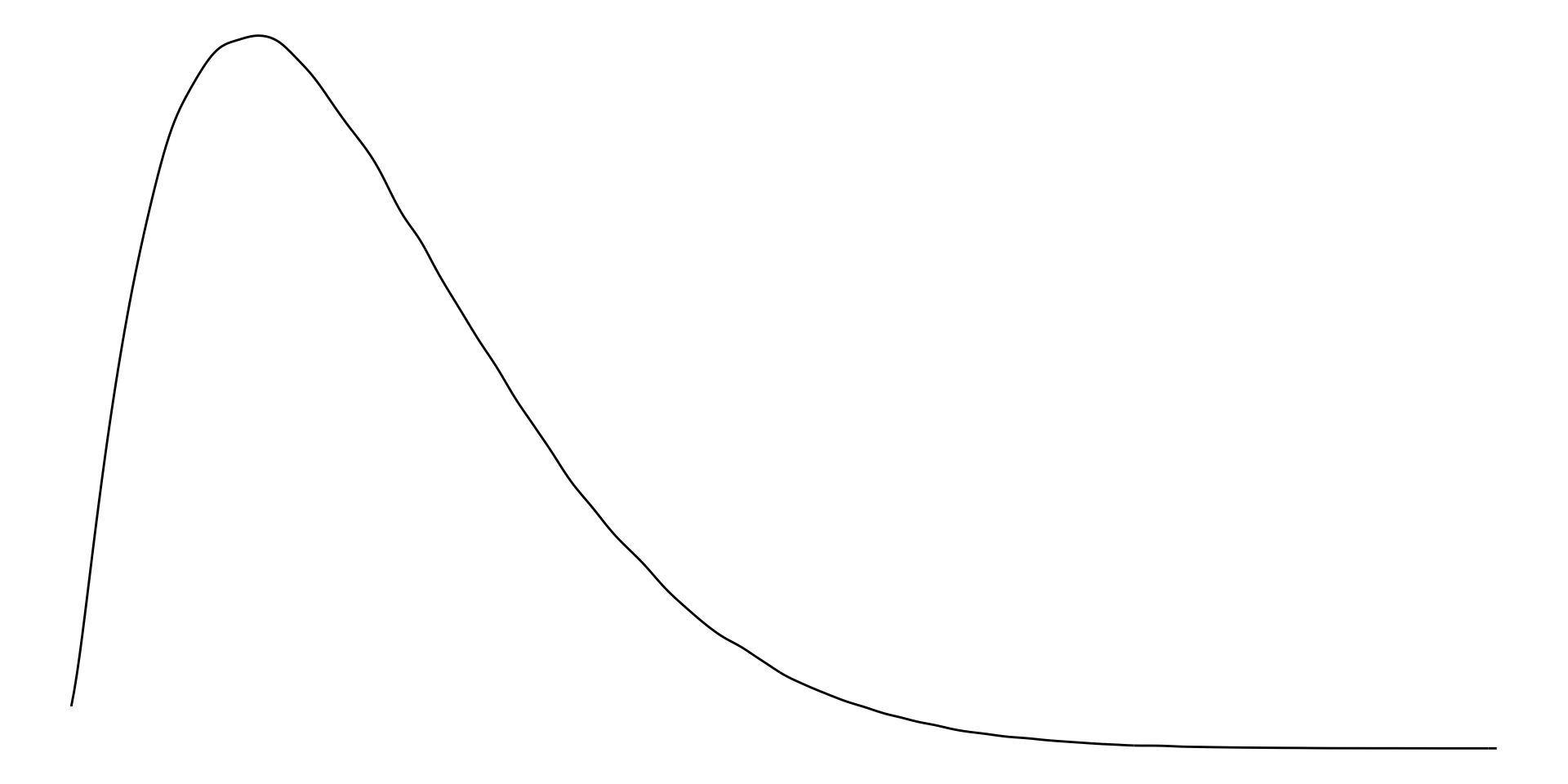
Left-skewed distribution
With left-skewed data, the majority of data have large values with a small number of small values. Examples of left-skewed data include democracies’ election turn-out rates.
ggplot() +
geom_density(aes(x = rbeta(1e6, 10, 2))) +
theme_void()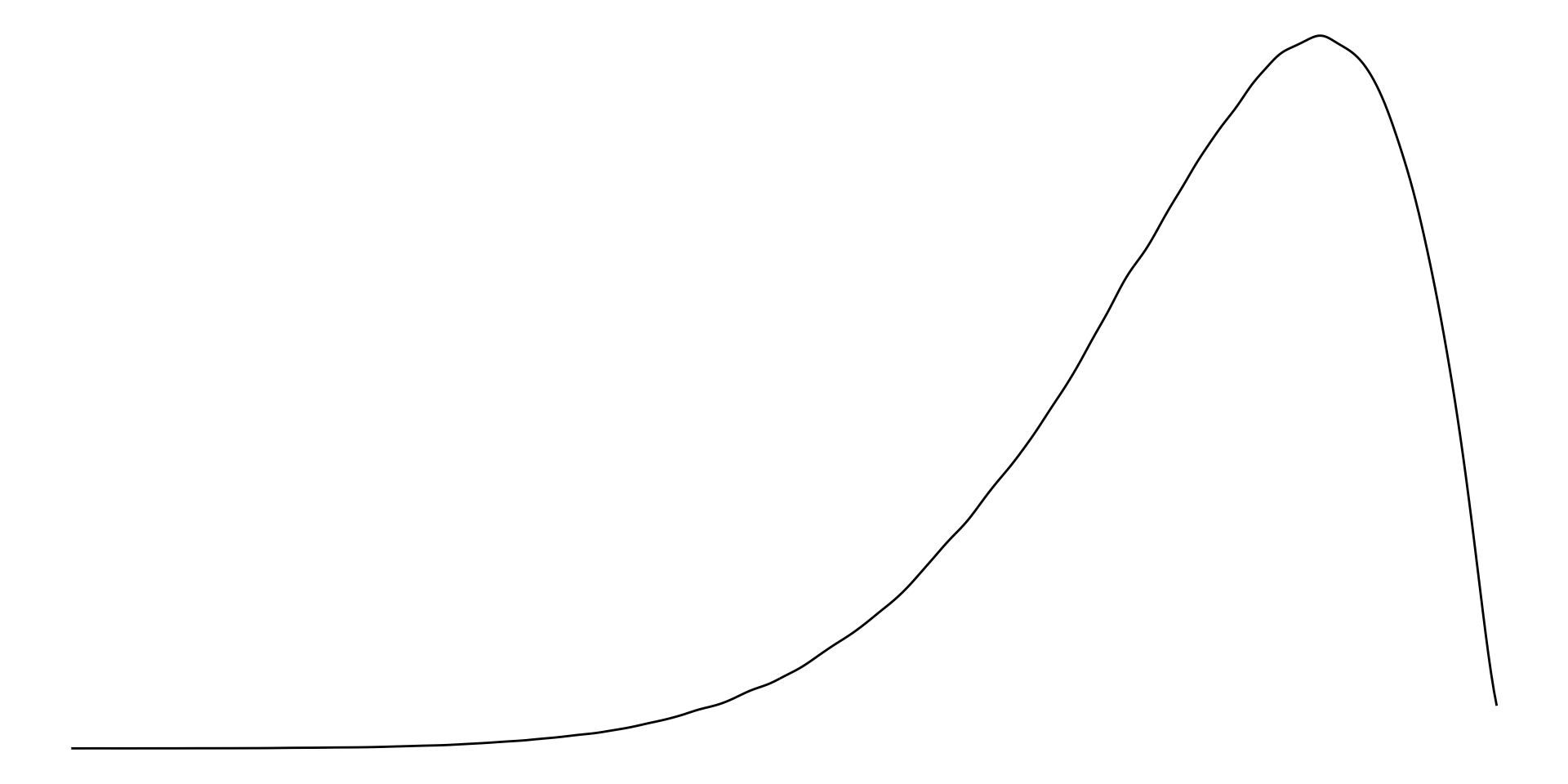
Measures of central tendency: mean, median, and mode
We can also use measures of central tendency to quickly describe and compare our variables.
Mean
The mean is the average of all values. Formally:
\[ \bar{x} = \frac{\Sigma x_i}{n} \]
In other words, add all of your values together and then divide that total by the number of values you have. We can use R to quickly calculate the mean percent of GDP spent on education by countries in 2020:
mean(perc_edu$value, na.rm = T)[1] 4.509317On average, countries spent 4.51% of their GDP on education in 2020.
Tip
If you do not use the argument na.rm (read “NA remove!”), you will get an NA if any exist in your vector of values. This is a good default! You should be very aware of missing data points.
Median
The median is the mid-point of all values. To calculate it, put all of your values in order from smallest to largest. Identify the value in the middle. That’s your median.
In R:
median(perc_edu$value, na.rm = T)[1] 4.446204The median country spent 4.45% of their GDP on education in 2020.
Tip
If you have an even number of observations, the median is the half-way-point between the two middle numbers of your ordered values (or the mean of those two middle values). For example, the median of all values from one to 10 is 5.5.
Mode
The mode is the most frequent of all values. To calculate it, count how many times each value occurs in your data set. The one that occurs the most is your mode.
Note
This is usually a more useful summary statistic for categorical variables than continuous ones. For example, which colour of car is most popular? Which political party has the most members?
We can find the modal region in our data set using base R’s table():
table(perc_edu$region)
East Asia & Pacific Europe & Central Asia
37 58
Latin America & Caribbean Middle East & North Africa
42 21
North America South Asia
3 8
Sub-Saharan Africa
48 The modal (or most common) region in our data set is Europe & Central Asia.
Using central tendency to describe and understand distributions
Normally distributed values have the same mean and median.
For right skewed data, the mean is greater than the median.
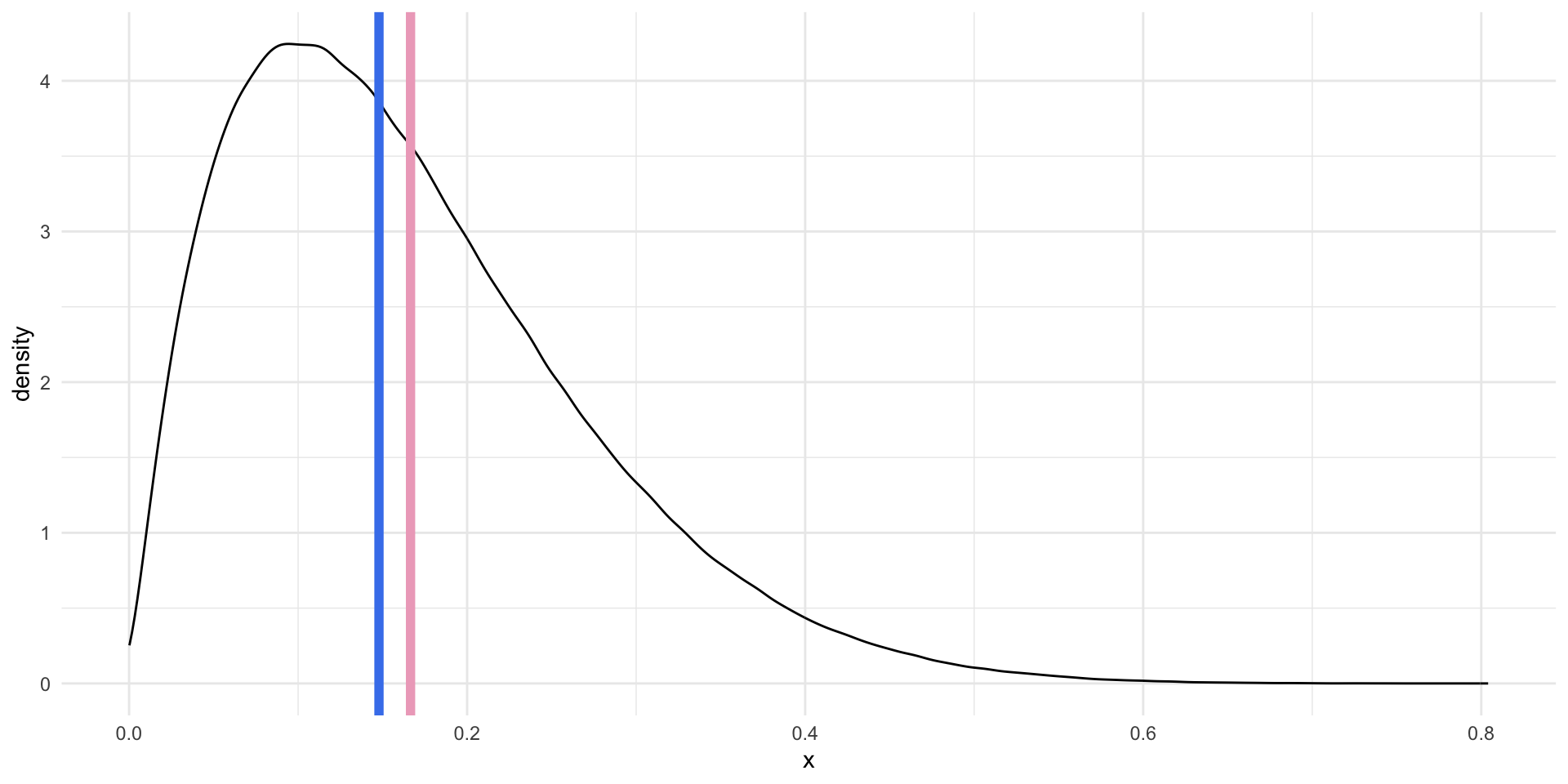
For left skewed data, the mean is smaller than the median.
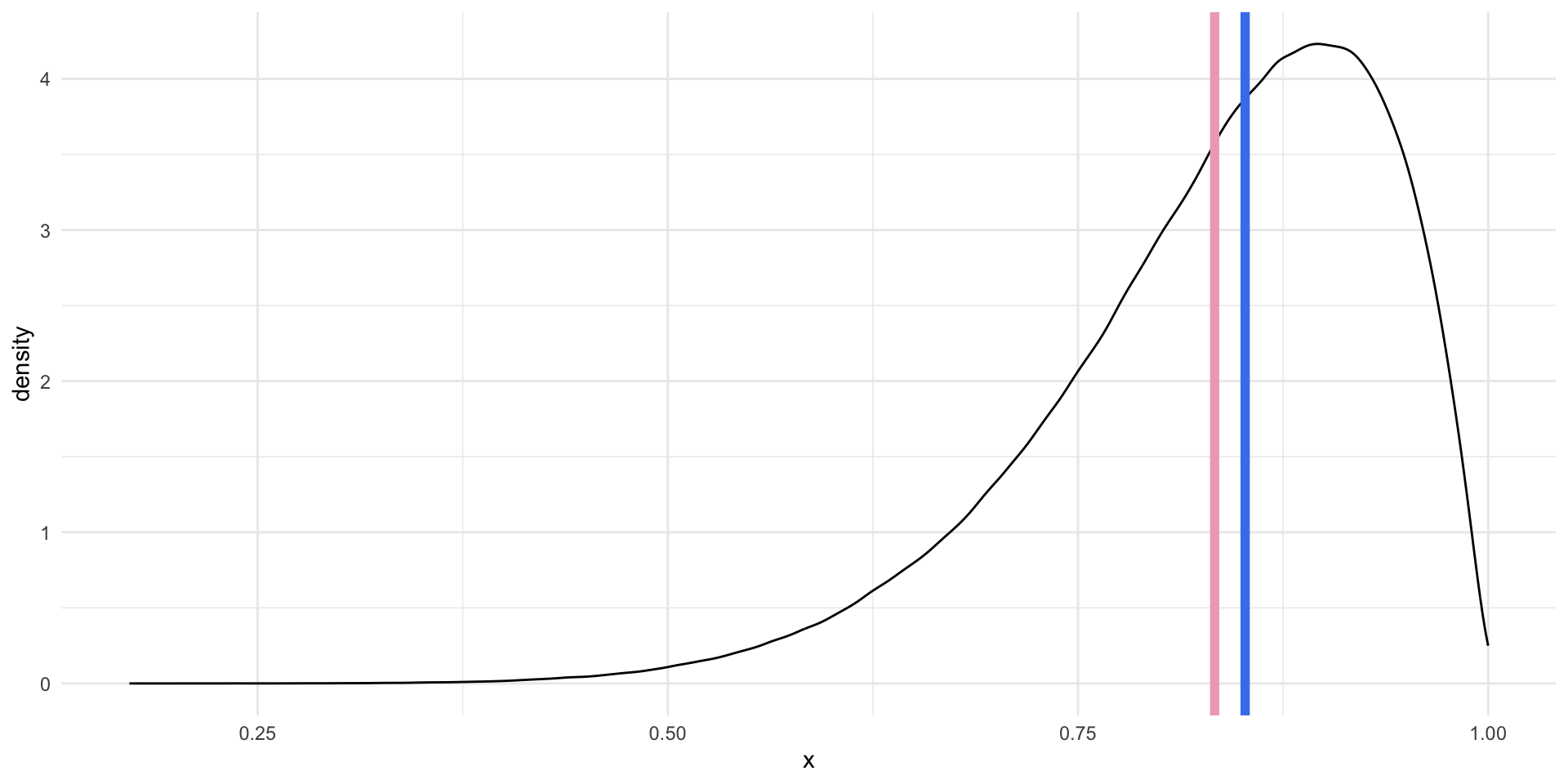
When do we care about the mean or the median? There is no simple answer to this question. Both of these values are useful summaries of our continuous data. We tend to use the average to describe our data in statistical analysis. As you will learn, most regression models are, fundamentally, just fancy averages of our data. However, this approach is not always sensible.
As you may have noted above, the average value is more sensitive to extreme values. If you have one very large or very small number in your vector of numbers, your average will be pulled well away from your mid-point (or median). This can lead you astray. To illustrate, let’s look at the average and median of the numbers between one and 10:
x <- 1:10
x [1] 1 2 3 4 5 6 7 8 9 10If we add one very large number to our vector, our average will shoot up but our median will only move up one additional number in our collection:
x <- c(x, 1000)
x [1] 1 2 3 4 5 6 7 8 9 10 1000Which number best summarizes our data? Here, I would suggest that the average is misleading. That one 1,000 data point is doing a lot of the work. The median better describes the majority of my data.
We will talk more about this (and outliers more specifically) later in this session.
Five number summary
As you can see, we are attempting to summarize our continuous data to give us a meaningful but manageable sense of it. Means and medians are useful for this.
We can provide more context to our understanding using more summary statistics. A common approach is the five number summary. This includes:
The smallest value;
The 25th percentile value, or the median of the lower half of the data;
The median;
The 75th percentile value, or the median of the upper half of the data;
The largest value.
We can use skimr::skim() to quickly get useful information about our continuous variable.
skim(perc_edu$value)| Name | perc_edu$value |
| Number of rows | 217 |
| Number of columns | 1 |
| _______________________ | |
| Column type frequency: | |
| numeric | 1 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| data | 52 | 0.76 | 4.51 | 1.75 | 0.36 | 3.3 | 4.45 | 5.53 | 10.54 | ▂▇▇▂▁ |
Alternatively, you can use base R’s summary():
summary(perc_edu$value) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.3596 3.2950 4.4462 4.5093 5.5270 10.5390 52 We have 217 rows (because our unit of observation is a country, we can read this as 217 countries2). We are missing education spending values for 52 of those countries (see n_missing or summary()’s NA's), giving us a complete rate of 76% (see complete_rate).
The country that spent the least on education as a percent of its GDP in 2020 was Nigeria, which spent only 0.4% (see p0). The country that spent the most was the Micronesia, Fed. Sts., which spent 10.5% (see p100). The average percent of GDP spent on education in 2020 was 4.5% (see mean) and the median was 4.4% (see p50).
This description was a bit unwieldy. As usual, to get a better sense of our data we should visualize it.
Box plots
Box plots (sometimes referred to as box and whisker plots) visualize the five number summary (with bonus features) nicely.
ggplot(perc_edu, aes(x = value)) +
geom_boxplot() +
theme_minimal() +
theme(
axis.text.y = element_blank()
) +
labs(
x = "Expenditure on education as a percentage of GDP",
y = NULL
)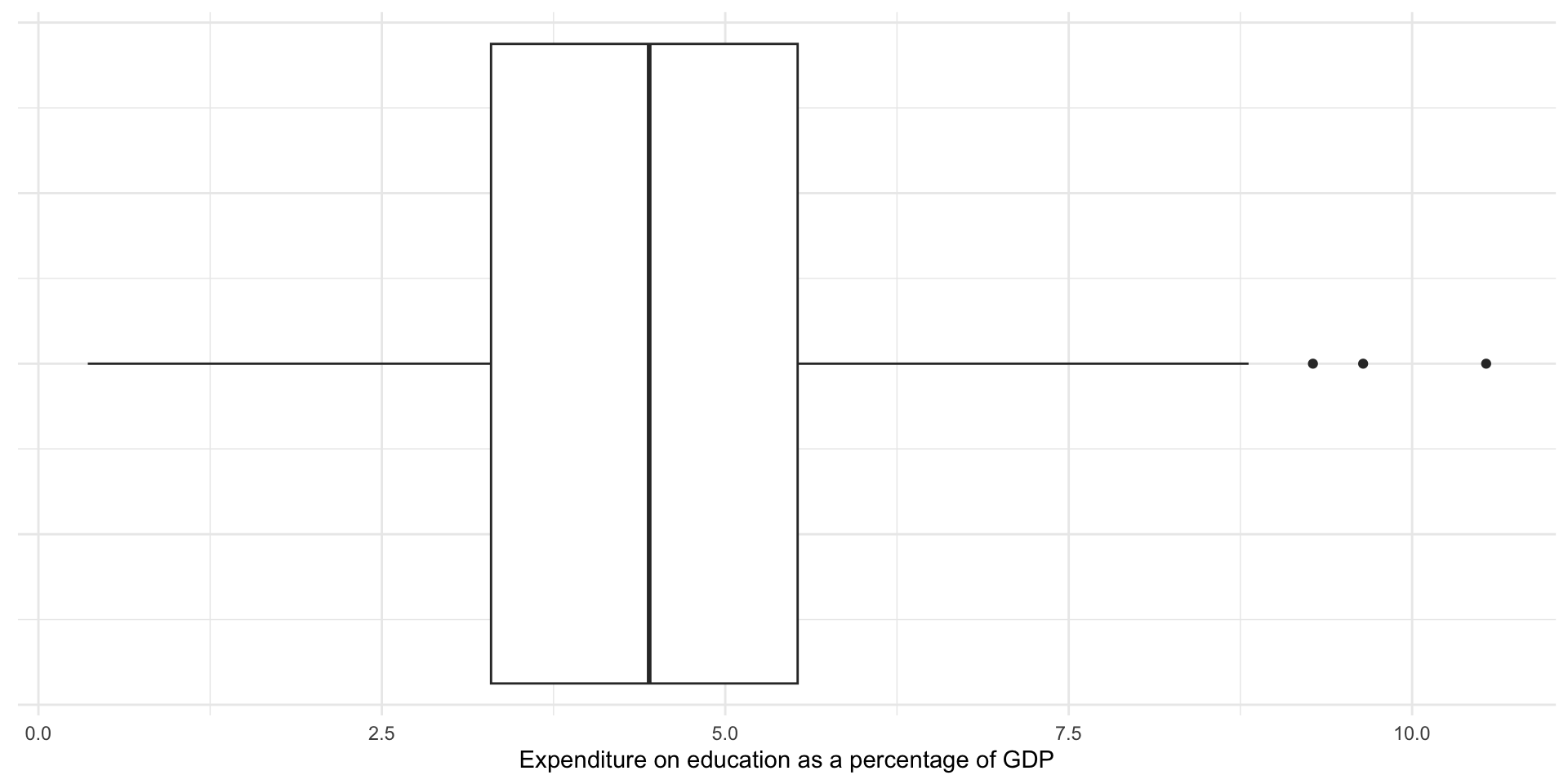
The box in the graph above displays the 25th percentile, the median, and the 75th percentile values. The tails show you all the data up to a range 1.5 times the interquartile range (IQR), or the 75th percentile minus the 25th percentile (or the upper edge of the box minus the lower edge of the box). If the smallest or largest values fall below or above (respectively) 1.5 times the IQR, the tail ends at that value. The remaining data points (if they exist) are displayed as dots shooting away from the whiskers of our box and whisker plot.
Outliers
Note that some countries’ expenditure are displayed as dots. The box plot above is providing you with a bit more information than the five number summary alone. If the data include values that fall outside of the IQR, they are displayed as dots. These are (very rule of thumb, take with a grain of salt, please rely on your theory and data generation process instead!) candidates for outliers.
Outliers fall so far away from the majority of the other values that they should be examined closely and perhaps excluded from your analysis. As discussed above, they can distort your mean. They do not, however, tend to distort your median.
Note
We will talk more about how to deal with outliers later in the course.
Measures of spread: range, variance, and standard deviation
We now have a good sense of some of the features of our data. Another useful thing to know is the shape of the distribution. Here, measures of spread are useful.
Range
The range is the difference between the largest and smallest value.
\[ range = max - min \]
In R:
The difference between the country that spends the highest proportion of its GDP on education and that which spends the least is 10.18 percentage points.
Variance
The variance measures how spread out your values are. On average, how far are your observations from the mean?
This measure can, at first, be a bit too abstract to get an immediate handle on. Let’s walk through it. Imagine we have two data sets, wide_dist and narrow_dist. Both are Normally distributed, share the same mean (0), and the same number of observations (1,000,000).
wide_dist# A tibble: 1,000,000 × 1
x
<dbl>
1 0.705
2 0.768
3 -0.291
4 -2.80
5 2.55
6 -0.684
7 2.25
8 1.91
9 -2.99
10 -1.92
# ℹ 999,990 more rowsnarrow_dist# A tibble: 1,000,000 × 1
x
<dbl>
1 -1.63
2 0.347
3 0.0396
4 -0.621
5 -0.594
6 0.526
7 -0.144
8 2.30
9 -0.0289
10 0.178
# ℹ 999,990 more rowsLet’s plot them:
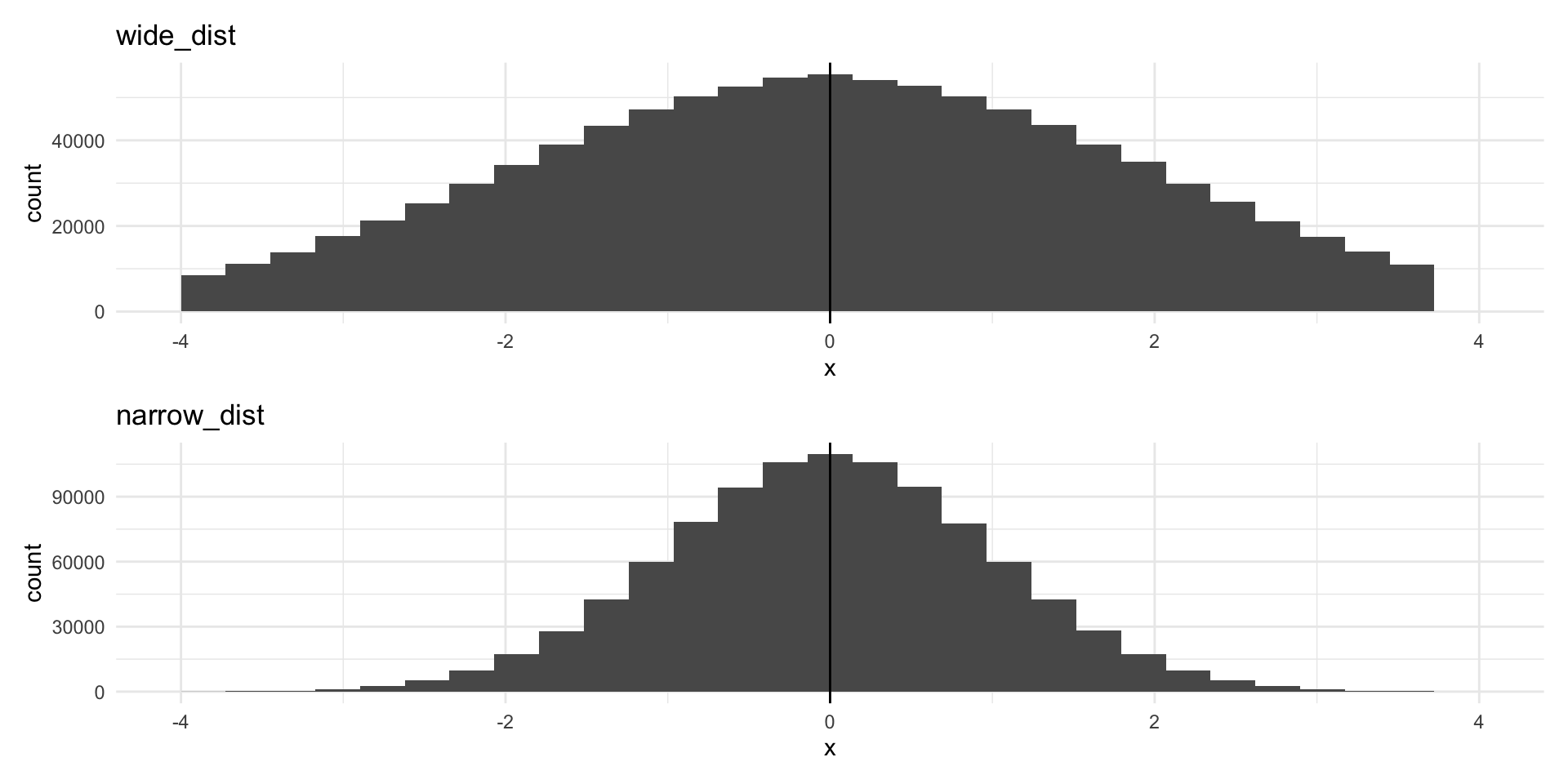
Despite both having the same center point and number of observations, the data are much more spread out around that center point in the top graph (of wide_dist).
The data in the top graph have higher variance (are more spread out) than those in the bottom graph. We measure this by calculating the average of the squares of the deviations of the observations from their mean.
\[ s^2 = \frac{\Sigma(x_i - \bar{x})^2}{n - 1} \]
Let’s step through this. We will first calculate the variance of wide_dist. To do this:
Calculate the mean of your values.
Calculate the difference between each individual value and that mean (how far from the mean is every value?).
Square those differences.
Tip
We do not care whether the value is higher or lower than the mean. We only care how far from the mean it is. Squaring a value removes its sign (positive or negative). Remember, if you multiply a negative number by a negative number, you get a positive number. This allows us to concentrate on the difference between each individual data point and the mean.
Add all of those squared differences to get a single number.
Divide that single number by the number of observations you have minus 1.
You now have your variance!
In R:
wide_dist_mean <- mean(wide_dist$x)
wide_var_calc <- wide_dist |>
mutate(
# Calculate the mean
mean = wide_dist_mean,
# Calculate the difference between each value and the mean
diff = x - mean,
# Square that difference
diff_2 = diff^2
)
wide_var_calc# A tibble: 1,000,000 × 4
x mean diff diff_2
<dbl> <dbl> <dbl> <dbl>
1 0.705 0.00161 0.703 0.494
2 0.768 0.00161 0.766 0.587
3 -0.291 0.00161 -0.292 0.0855
4 -2.80 0.00161 -2.81 7.87
5 2.55 0.00161 2.55 6.49
6 -0.684 0.00161 -0.686 0.471
7 2.25 0.00161 2.25 5.05
8 1.91 0.00161 1.91 3.65
9 -2.99 0.00161 -2.99 8.95
10 -1.92 0.00161 -1.92 3.69
# ℹ 999,990 more rowsWe the add those squared differences between each observation and the mean of our whole sample together. Finally, we divide that by one less than our number of observations.
We can compare this to the variance for our narrower distribution.
narrow_var_calc <- narrow_dist |>
mutate(
mean = mean(narrow_dist$x),
diff = x - mean,
diff_2 = diff^2
)
narrow_var <- sum(narrow_var_calc$diff_2) / (nrow(narrow_var_calc) - 1)
narrow_var[1] 0.9980407It is, in fact, smaller!
That was painful. Happily we can use base R’s var() to do this in one step:
var(wide_dist) x
x 4.006904var(narrow_dist) x
x 0.9980407On average, countries spent 3.06% more or less than the average of 4.51% of their GDP on education in 2020.
Standard deviation
A simpler measure of spread is the standard deviation. It is simply the square root of the variance.
sqrt(wide_var)[1] 2.001725sqrt(narrow_var)[1] 0.9990198You can get this directly using base R’s sd():
sd(wide_dist$x)[1] 2.001725sd(narrow_dist$x)[1] 0.9990198The standard deviation of all countries’ percentage of their GDP that they spent on education in 2020 was 1.75%. This horrible sentence demonstrates that standard deviations are most usefully employed in contexts other than attempts to better describe your variables of interest. For example, they are very important for determining how certain we can be about the relationships between different variables we uncover using statistical models (which we will get to later in the course).
Conclusion
Your empirical analysis is only as strong as its foundation. You can use the tools you learnt this session to build a very strong foundation. Always start any analysis by getting a very good sense of your data. Look at it with a critical eye. Does it match your intuition? Is something off? What can you learn about the peaks and troughs among your observations?
Quiz
Head over to ELMs to complete this session’s quiz. You need to score 80% on it to gain access to the next session’s quiz.
Footnotes
The Comprehensive R Archive Network (CRAN) hosts many R packages that can be installed easily using the familiar
install.packages()function. These packages have gone through a comprehensive quality assurance process. I wrotepolisciolsfor this class and will update it regularly. I, therefore, will not host it through CRAN: the quality assurance process takes too long to be practical for our weekly schedule. Instead, you are downloading it directly from its Github repository.↩︎You are right: there were not 217 countries in 2020. The World Bank collects data on some countries that are not members of the UN (and would not, traditionally, be considered to be countries).↩︎