install.packages(c("broom", "ggridges", "modelsummary"))Relationships Between Two Variables
Set up
Installing packages
If you have not already done so, please install or update these packages by running the following in your console:
library(tidyverse)
library(wbstats)
library(poliscidata)
library(countrycode)
library(broom)
library(janitor)
library(ggridges)
library(modelsummary)How will what you learn this week help your research?
As usual, we start with an interesting question. You have some outcome of interest and you think that there is an important determinant of that outcome that no one has yet identified. Or perhaps the relationship between some heavily chewed over determinant and the outcome of interest is misunderstood. We are steadily building up your ability to determine empirically the relationship between that determinant and the outcome of interest.
Simply put (and there really is no need to over-complicate this), we have two or more variables: an outcome of interest (the dependent variable) and a set of independent variables that we theorize are important determinants of that outcome. We can use empirical analysis to understand 1) how the dependent and independent variables change in relation to one another, and 2) whether this relationship is strong enough that we should declare (though 12,000-word journal articles or by shouting from rooftops) that whenever we want to change or understand that outcome, we must consider these important independent variables.
Previously, we discussed various tools that you can use to explore your data. This is very important for building your intuition and, by extension, your expertise in the question at hand. These tools also allow you to identify unusual data points (or outliers).
This week, we will make the next step. We will explore how two variables relate to each other. How do they move with each other: when one goes up, does the other go down, up, or not really move? How strong is this association?
This exploration is particularly important for you to do with regard to the independent variable(s) that are the focal point of your theory and, therefore, your contribution to our understanding of the messy spaghetti bowl of things that determine your outcome of interest. Just as it is important for you to spend some time understanding the shape of your variables (using the tools we discussed last week), you must also start to understand the shape of the relationship between the outcome you are trying to understand or predict and the factors you think are important determinants of that outcome.
Let’s begin!
Bivariate relationships
How do two variables move with one another? When when goes up, does the other go down, up, or not really move at all? How dramatic is this shift?
The type of variables we have determines how we can answer this question. To begin, we will explore the relationship between two continuous variables. Later in the class, we will look at how to explore the relationship between a continuous and categorical variable.
To start, we will explore the relationship between wealth and health. This question was made popular by Hans Rosling’s Gapminder project.
Collecting our data
First, we need to collect our data. Following Rosling, we will use each country’s average life expectancy to measure its health and the country’s GDP per capita to measure its wealth. We will use wbstats::wb_data() to pull these data directly from the World Bank.
gapminder_df <- wb_data(
indicator = c("SP.DYN.LE00.IN", "NY.GDP.PCAP.CD"),
start_date = 2016,
end_date = 2016
) |>
rename(
life_exp = SP.DYN.LE00.IN,
gdp_per_cap = NY.GDP.PCAP.CD
) |>
mutate(
log_gdp_per_cap = log(gdp_per_cap),
region = countrycode(country, "country.name", "region", custom_match = c("Turkiye" = "Europe & Central Asia"))
) |>
relocate(region, .after = country)
gapminder_df# A tibble: 217 × 8
iso2c iso3c country region date gdp_per_cap life_exp log_gdp_per_cap
<chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 AW ABW Aruba Latin… 2016 27442. 75.5 10.2
2 AF AFG Afghanistan South… 2016 522. 62.6 6.26
3 AO AGO Angola Sub-S… 2016 1808. 61.6 7.50
4 AL ALB Albania Europ… 2016 4168. 78.6 8.34
5 AD AND Andorra Europ… 2016 40130. 84.5 10.6
6 AE ARE United Arab Em… Middl… 2016 41326. 82.2 10.6
7 AR ARG Argentina Latin… 2016 12700. 76.1 9.45
8 AM ARM Armenia Europ… 2016 3524. 74.9 8.17
9 AS ASM American Samoa East … 2016 12843. 72.6 9.46
10 AG ATG Antigua and Ba… Latin… 2016 16557. 77.0 9.71
# ℹ 207 more rowsWhat is the relationship between these two variables?
What is the relationship between a country’s average life expectancy and its GDP per capita? The easiest way to determine this is to visualize these two variables.
ggplot(gapminder_df, aes(x = gdp_per_cap, y = life_exp)) +
geom_point() +
theme_minimal() +
labs(x = "GDP per capita (USD current)",
y = "Average life expectancy (years)") +
scale_x_continuous(labels = label_dollar())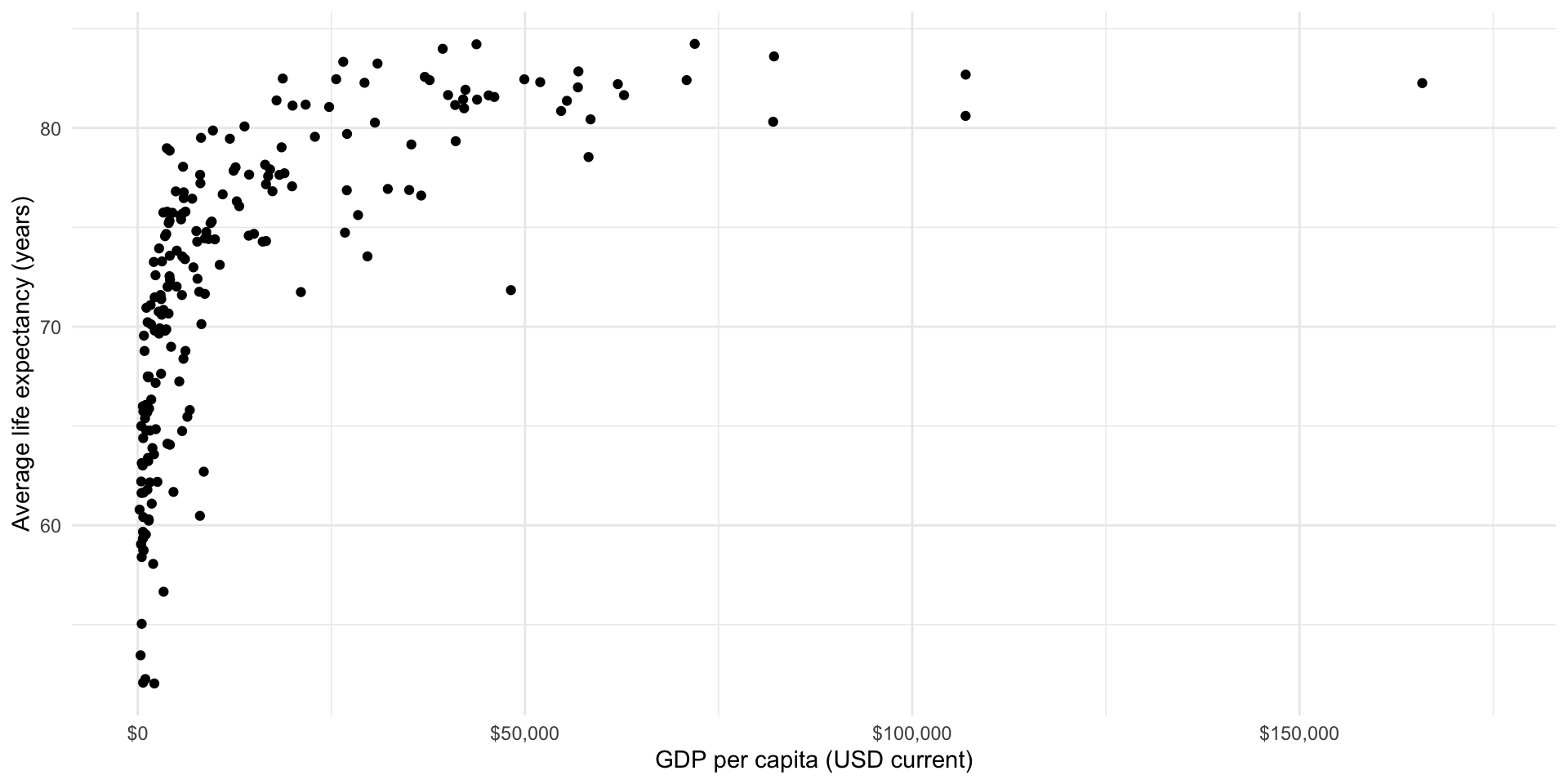
There seems to be a good case that there is a strong relationship between a country’s GDP per capita (wealth) and its average life expectancy (health). It appears that we expect citizens that live in countries that have larger GPD per capita to live longer, on average. But this relationship is not linear (a straight line drawn through them will not summarise this very well).
Because we want to explore linear relationships at this stage of the course, we will look at the logged GDP per capita variable:
ggplot(gapminder_df, aes(x = log_gdp_per_cap, y = life_exp)) +
geom_point() +
theme_minimal() +
labs(x = "Logged GDP per capita",
y = "Average life expectancy (years)") +
scale_x_continuous(labels = label_dollar())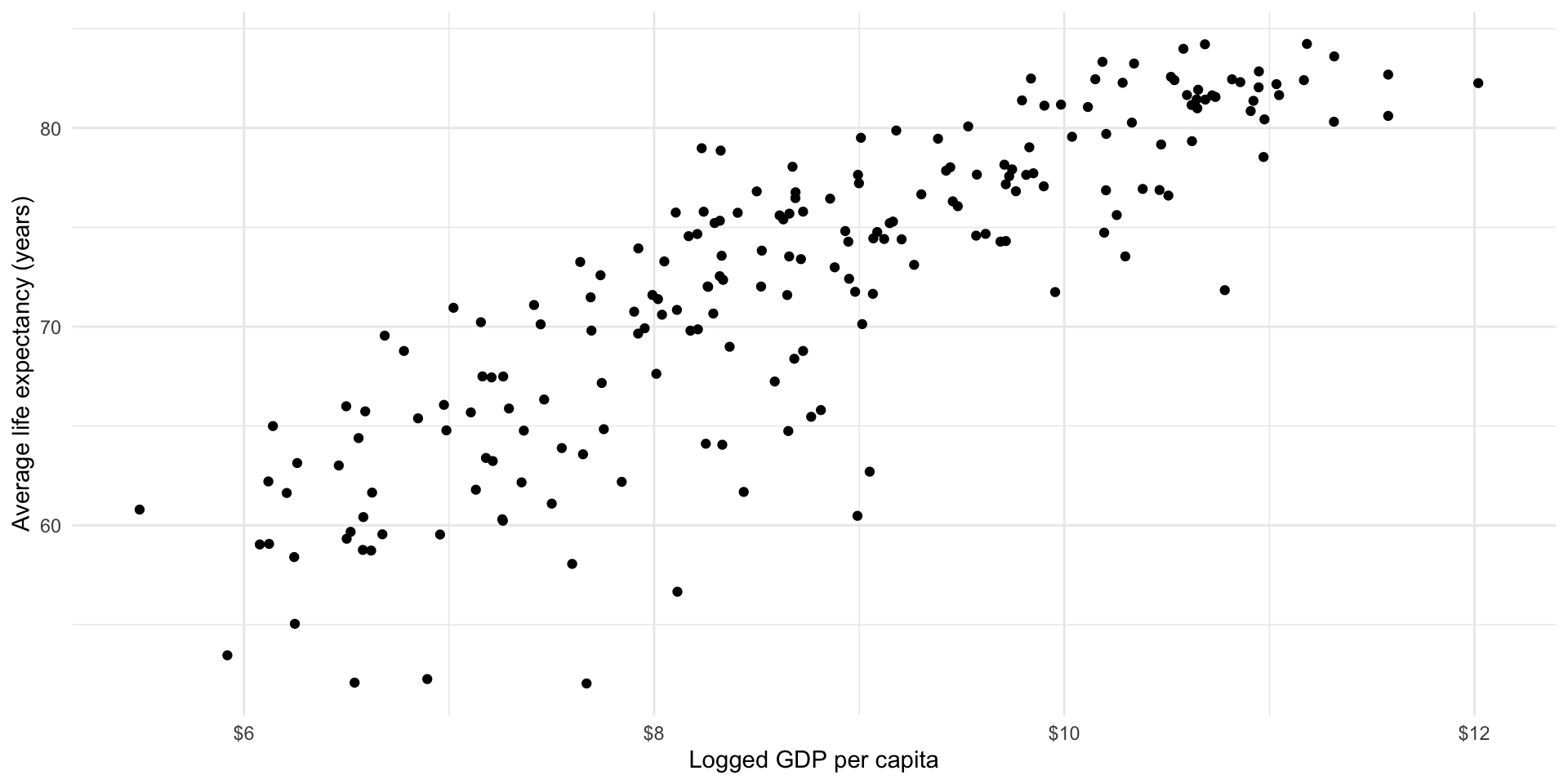
Note
You can transform your data to make it easier to work with. Just remember that you now need to talk in terms of logged GDP per capita instead of GDP per capita.
I can imagine drawing a straight line among these points that summarises how they vary with each other. It appears that as a country’s logged GDP per capita increases, so too does the average life expectancy of its population. As wealth increases, so too does health.
Well, that was easy! What is the relationship between health and wealth? They increase with each other.
How can we measure the strength of that relationship?
Now we need some way of measuring the strength of the relationship. In other words, what amount of the variation in countries’ average life expectancy is associated with variation in their GDP per capita? We can measure the strength of this association using correlations. The correlation coefficient tells us how closely variables relate to one another. It tells us both the strength and direction of the association.
- Strength: how closely are these values tied to one another. Measured from 0 to |1|, with values closer to 0 indicating a very weak relationship and values closer to |1| indicating a very strong relationship.
Tip
What are those funny looking |s? They represent the absolute value, which is shorthand for the number regardless of its sign. To demonstrate, |1| is the absolute value of 1 and -1.
- Direction: do both \(X\) and \(Y\) change in the same direction? Positive correlations show that when \(X\) increases (decreases), so does \(Y\). Negative correlations show that when \(X\) increases (decreases), \(Y\) decreases (increases). In other words, they move in different directions.
What is the correlation between logged GDP per capita and life expectancy?
cor(gapminder_df$log_gdp_per_cap, gapminder_df$life_exp, use = "complete.obs")[1] 0.8538064As expected, the relationship is positive and strong.
Building a generalizable description of this relationship
We have very quickly gained the skills to determine whether the relationship between two variables is positive, negative, or non-existent. We have also learnt how to describe the strength of that relationship. To that end, we are now able to describe the bivariate relationship between health and wealth as a positive and strong one.
This is useful, but we tend to need a more concrete way of describing the relationship between two variables. For example, what if a policy-maker comes up to you and asks what you think the effect of a $1,000 increase in a country’s GDP per capita will do to its average life expectancy? We can build simple models of this relationship to provide that policy-maker with a prediction of what we might expect to happen on average. Further, we can use the model to describe the relationship between these two variables in a generalized way. If a new country were to spring into existence, we can use our knowledge of its GDP per capita to determine how long we might expect its citizens to live.
OLS and linear regression
Looking back at our data, we can image a straight line running between each country’s plotted average life expectancy and GDP per capita. Let’s draw that line.
ggplot(gapminder_df, aes(x = log_gdp_per_cap, y = life_exp)) +
geom_point() +
theme_minimal() +
labs(x = "Logged GDP per capita",
y = "Average life expectancy (years)") +
scale_x_continuous(labels = label_dollar())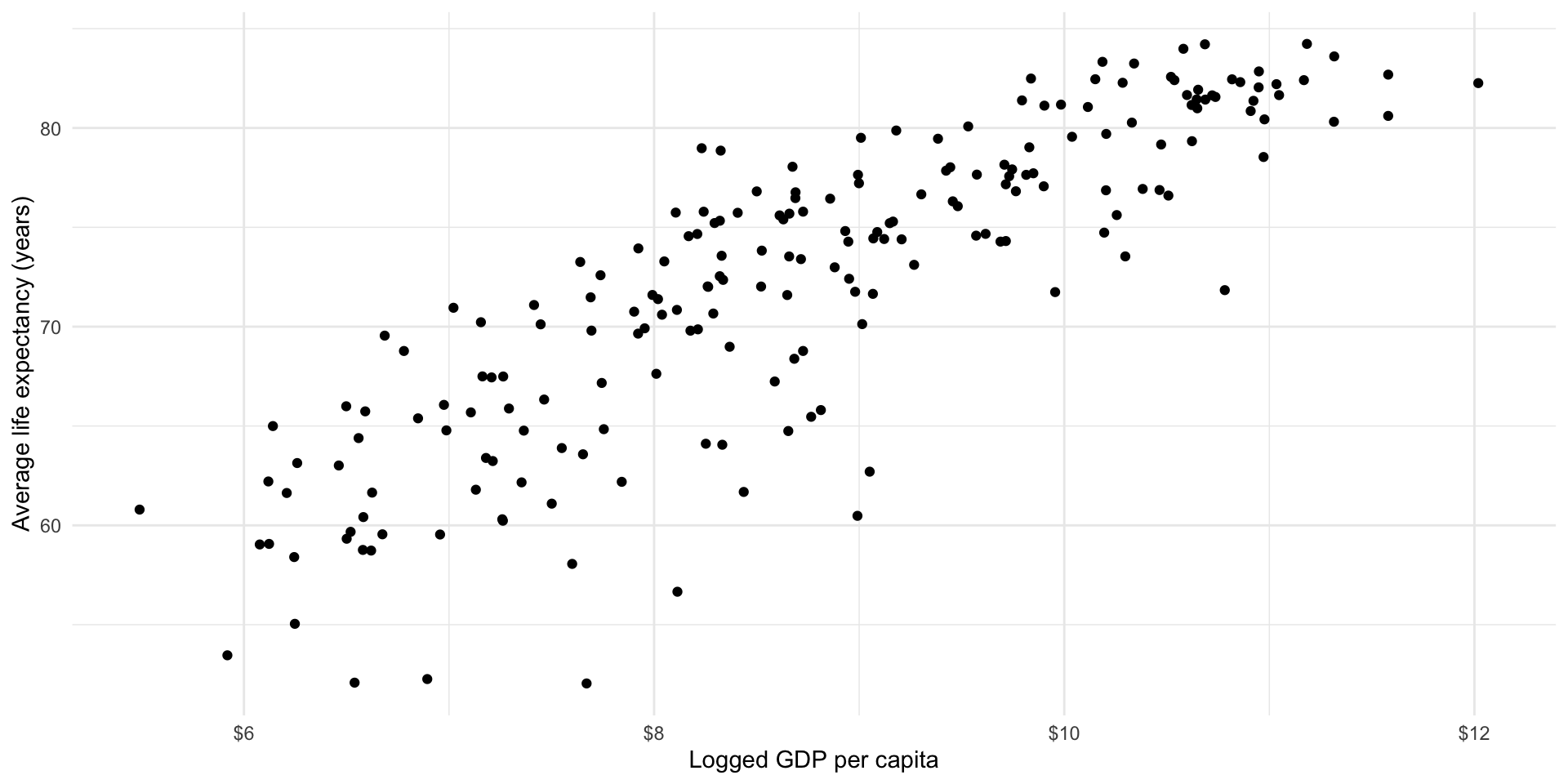
We can, of course, draw many different lines through these points. Each of us has probably drawn a slightly different line in our heads. Which is the best line? Ordinary least squares (OLS) regression provides an answer. Simply put, OLS regression draws the line that minimizes the distance between itself and all of the data points. That line can take many shapes, including a straight line, an S, a frowney face, and smiley face, etc.
Looking at our data above, it appears that a straight line is the best line to draw.
Note
Overfitting involves fitting a model (or drawing a line through our data) that misses the forest for the trees. You can draw all kinds of shapes through those data that perhaps result in a smaller distance between itself and each dot. In fact, if you draw a line that connects all of those dots there will be no difference between your line and the data points. However, this model will be too focused on the data we have at hand. Our model will have no idea what to do with any new data points we introduce. This is bad! Your aim here is to produce a generalizable model of the relationship between these two variables, not to draw a line that connects this particular constellation of dots.
Okay, so a straight line is the best type of line to draw. But there are still many, many different straight lines that we can draw. Which straight line is best? Remember, OLS regression finds the line that minimizes the distance between itself and all of the data points. Let’s step through this. Look at the graph above.
Draw a line through those dots. Pick a line, any line!
Calculate the distance between each dot and the line.
Sum up the absolute values of those distances. Remember, we just care about the distance, so we don’t need to worry about whether or not the dots are above or below the line.
Repeat steps 1 - 3 many, many, many times.
Pick the line with the smallest sum of distances (or results from step 3).
Phew, this seems tedious. Happily, maths and R are to the rescue. Here is the line that minimizes those distances (all with the addition of one extra line of code).
ggplot(gapminder_df, aes(x = log_gdp_per_cap, y = life_exp)) +
geom_point() +
geom_smooth(method = "lm", se = F) +
theme_minimal() +
labs(x = "Logged GDP per capita",
y = "Average life expectancy (years)") +
scale_x_continuous(labels = label_dollar())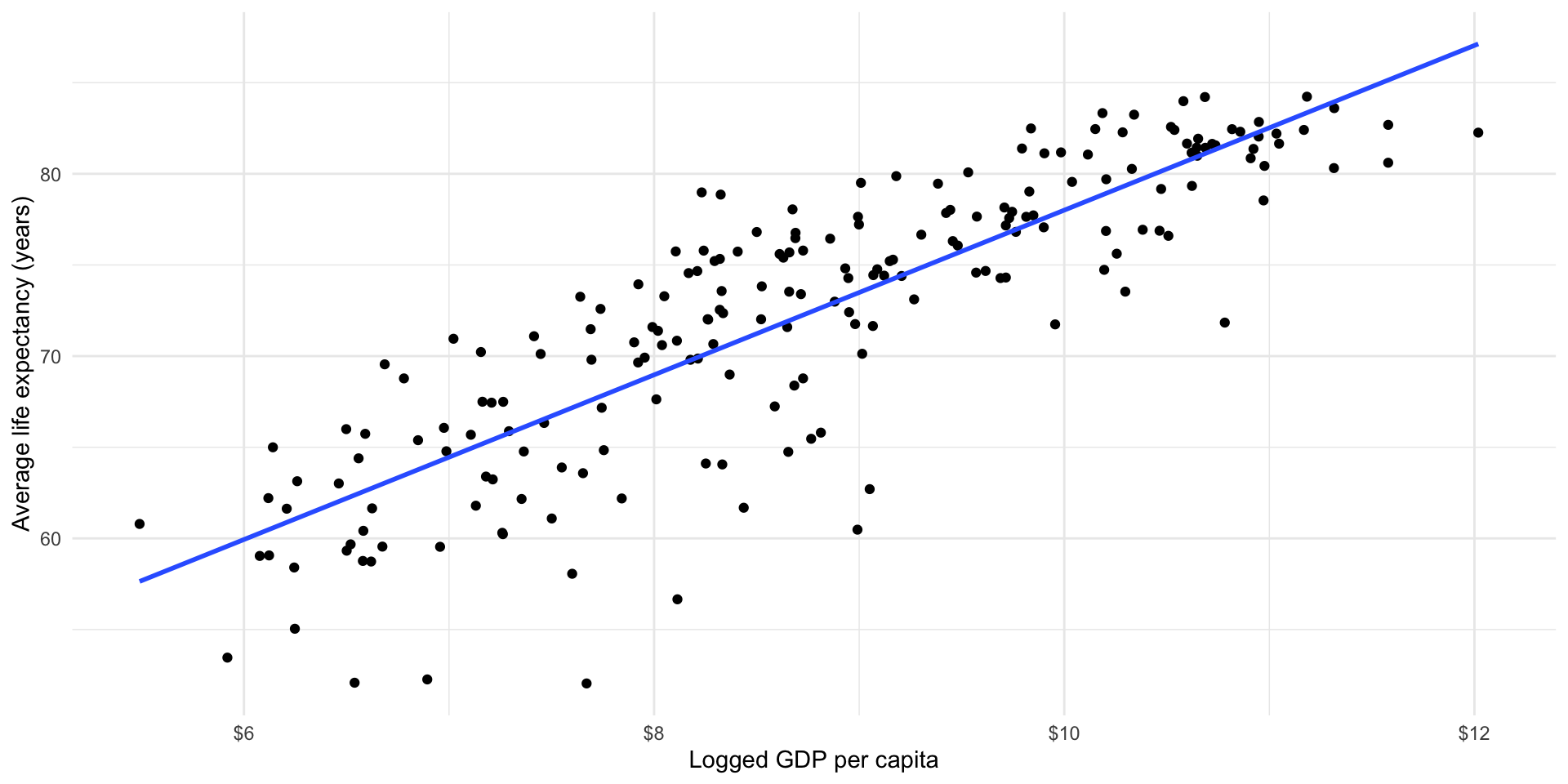
Estimating a linear model in R
How did R do this? To answer this, we will first do some review.
Remember the general equation for a line:
\[ y = a + mx \]
Read this as: the value of \(y\) is the sum of some constant, \(a\), and some \(x\) variable that has been transformed by some slope value \(m\).
Note
Remember that the slope constant, \(m\), tells you how much \(y\) changes for every one unit increase in \(x\).
So, if:
\[ y = 10 + 2x \]
Then, when \(x = 20\):
\[ y = 10 + 2*20 = 50 \]
For many values of \(x\):
ggplot(tibble(x = 0:50, y = 10 + 2*x), aes(x = x, y = y)) +
geom_line(colour = "lightgrey", linewidth = 3) +
geom_point() +
theme_minimal()
Well, let’s substitute in our variables of interest. Our \(y\) variable is a country’s average life expectancy and our \(x\) variable is that country’s logged GDP per capita.
\[ life Exp_x = \beta_0 + \beta_1 logGdpPerCap_x + \epsilon \]
Read this as: a country’s average life expectancy is a function of some constant (\(\beta_0\)) and its logged GDP per capita transformed by some value \(\beta_1\) with some random error (\(\epsilon\)), on average.
Let’s imagine that this relationship is accurately described by the following formula:
\[ life Exp_x = 30 + 4 * logGdpPerCap_x \]
Note
We will get to that pesky error term in just a minute.
Then, our model would predict the following average life expectancy for countries with log GDPs per capita between 0 and 20:
ggplot(
tibble(log_gdp_per_cap = 0:20, life_exp = 30 + 4*log_gdp_per_cap),
aes(x = log_gdp_per_cap, y = life_exp)
) +
geom_line(colour = "lightgrey", linewidth = 3) +
geom_point() +
theme_minimal() +
labs(x = "Logged GDP per capita",
y = "Average life expectancy (years)") +
scale_x_continuous(labels = label_dollar())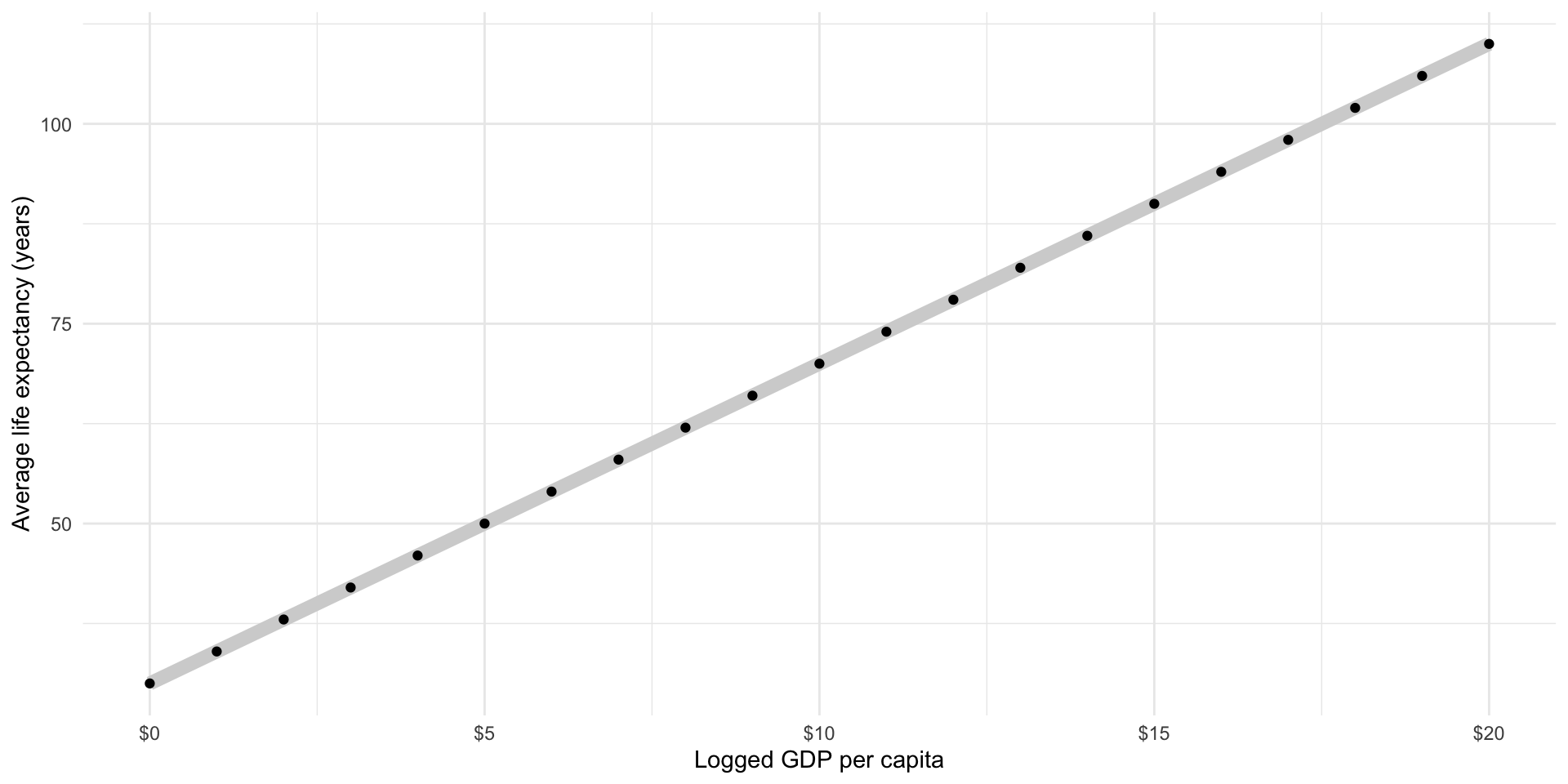
A country with a logged GDP per capita of 5 (the equivalent of a GDP per capita of $148.41) has a predicted average life expectancy of 50 years, or \(30 + 4*5\).
A country with a logged GDP per capita of 10 (the equivalent of a GDP per capita of $22,026.47) has a predicted average life expectancy of 70 years, or \(30 + 4*10\).
Does this accurately describe what we see in our data? What is the average life expectancy for countries with roughly $22,000 GDP per capita?
countries_10 <- filter(gapminder_df, gdp_per_cap > 21000 & gdp_per_cap < 23000)
countries_10# A tibble: 3 × 8
iso2c iso3c country region date gdp_per_cap life_exp log_gdp_per_cap
<chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 KN KNA St. Kitts and N… Latin… 2016 21388. 71.2 9.97
2 SA SAU Saudi Arabia Middl… 2016 22268. 78.4 10.0
3 SI SVN Slovenia Europ… 2016 21448. 81.2 9.97We predicted 70 years, but our data suggest that these countries have closer to an average of 77 years. Why do we have this difference?
Well, we probably haven’t produced the best model we can (this isn’t the best line!). We just picked those numbers out of thin air. Let’s fit a linear OLS regression and see if we improve our ability to predict what we have seen in the wild.
How do we calculate the constant (\(\beta_0\)) using OLS regression?
Remember, OLS regression simply finds the line that minimizes the distance between itself and all the data points. The constant that minimizes this distance is the mean of \(Y\) minus \(\beta_1\) times the mean of \(X\).
So, the constant that best predicts a country’s average life expectancy based on its logged GDP per capita is equal to the average life expectancy across our sample (72.35 years) minus the average logged GDP per capita ($8.81, or $6,672.83 GDP per capita) transformed by \(\beta_1\).
So…
How do we calculate the coefficient \(\beta_1\)?
The regression slope is the correlation coefficient between \(X\) and \(Y\) multiplied by the standard deviation of \(Y\) divided by the standard deviation of \(X\).
Ew… Let’s step through that.
Remember, the correlation coefficient simply measures how \(X\) and \(Y\) change together. Does \(Y\) increase when \(X\) increases? How strong is this relationship?
The standard deviations of \(X\) and \(Y\) just measure how spread out they are.
Bringing these together, we are interested in how much \(X\) and \(Y\) change together moderated by how much they change independently of each other.
Formally:
\[ \beta_1 = (\frac{\Sigma(\frac{x_i - \bar{x}}{s_X})(\frac{y_i - \bar{y}}{s_Y})}{n - 1})(\frac{s_Y}{s_X}) = \frac{\Sigma(x_i - \bar{x})(y_i - \bar{y})}{\Sigma(x_i - \bar{x})^2} \]
Happily R does all of this for us.
Let’s fit that model already!
m <- lm(life_exp ~ log_gdp_per_cap, data = gapminder_df)
m
Call:
lm(formula = life_exp ~ log_gdp_per_cap, data = gapminder_df)
Coefficients:
(Intercept) log_gdp_per_cap
32.422 4.544 Okay, so the line of best fit describing the relationship between life expectancy and logged GDP per capita is:
\[ life Exp_x = 32.9 + 4.5 * logGdpPerCap_x + \epsilon \]
That’s it! We now have a generalized model of the relationship between a country’s average life expectancy and its logged GDP per capita. This model is informed by what we actually observed in the world. It carefully balances our need to accurately describe what we have observed and to develop something that is generalizable.
The above model output is difficult to read. It will not be accepted by any journal or professor. Luckily, we can use modelsummary::modelsummary() to easily generate a professionally formatted table.
modelsummary(
m,
statistic = NULL,
coef_rename = c("log_gdp_per_cap" = "GDP per capita (logged)"),
gof_map = "nobs"
)| (1) | |
|---|---|
| (Intercept) | 32.422 |
| GDP per capita (logged) | 4.544 |
| Num.Obs. | 210 |
Note that OLS regression, particularly linear regression, requires that you make a lot of important assumptions about the relationship between your two variables. These were discussed in detail in the lecture. For example, we assume that the best line to fit is straight. We also assume that the best way to generate and describe the relationship across all observations is to fit the line that minimizes the distance between itself and the observed values or dots.
Note
There are other approaches to determining the “best” line. These include maximum likelihood estimation (discussed in detail in GVPT729) and Bayesian statistics. We won’t discuss these approaches in this class or in GVPT722. It’s worth noting here; however, that OLS regression requires a whole bunch of assumptions that may or may not be appropriate to your research question or theory. This class prepares you to grapple with those questions and appropriately use these tools in your own research.
Prediction and performance
Okay, so we now have a model that describes the relationship between our outcome of interest (health) and our independent variable of interest (wealth). We can use this to predict our outcome of interest for different values of our independent variable. For example, what do we predict to be the average life expectancy of a country with a GDP per capita of $20,000?
broom::tidy(m) makes this model object a lot easier (tidier) to work with.
tidy(m)# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 32.4 1.72 18.9 4.82e-47
2 log_gdp_per_cap 4.54 0.192 23.7 6.94e-61First, let’s pull out the estimated constant (or intercept or \(\beta_0\)) for our calculations.
m_res <- tidy(m)
beta_0 <- m_res |>
filter(term == "(Intercept)") |>
pull(estimate)
beta_0[1] 32.42236Next, let’s pull out the estimated coefficient for (logged) GDP per capita:
beta_1 <- m_res |>
filter(term == "log_gdp_per_cap") |>
pull(estimate)
beta_1[1] 4.544133Finally, we can plug this in to our model:
\[ life Exp_x = \beta_0 + \beta_1 logGdpPerCap_x \]
life_exp_20000 <- beta_0 + beta_1 * log(20000)
life_exp_20000[1] 77.42513A country with a GDP per capita of $20,000 is predicted to have an average life expectancy of 77 years. Let’s take a look back at our data. Remember, these data describe what the World Bank actually observed for each country in 2016. How close is our predicted value to our observed values?
countries_10# A tibble: 3 × 8
iso2c iso3c country region date gdp_per_cap life_exp log_gdp_per_cap
<chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 KN KNA St. Kitts and N… Latin… 2016 21388. 71.2 9.97
2 SA SAU Saudi Arabia Middl… 2016 22268. 78.4 10.0
3 SI SVN Slovenia Europ… 2016 21448. 81.2 9.97As above, our data suggest that these countries have closer to an average of 77 years. Although our model predicted an average life expectancy closer to this than our guess above (which predicted 70 years), we still have a gap. Why?
Our model is an attempt to formalize our understanding of the general relationship between a country’s wealth and health. Mapping our model against the observed values we used to generate it illustrates this point well.
ggplot(gapminder_df, aes(x = log_gdp_per_cap, y = life_exp)) +
geom_point() +
geom_vline(xintercept = log(20000)) +
geom_hline(yintercept = life_exp_20000) +
geom_smooth(method = "lm", se = F) +
theme_minimal() +
labs(x = "Logged GDP per capita",
y = "Average life expectancy (years)") +
scale_x_continuous(labels = label_dollar())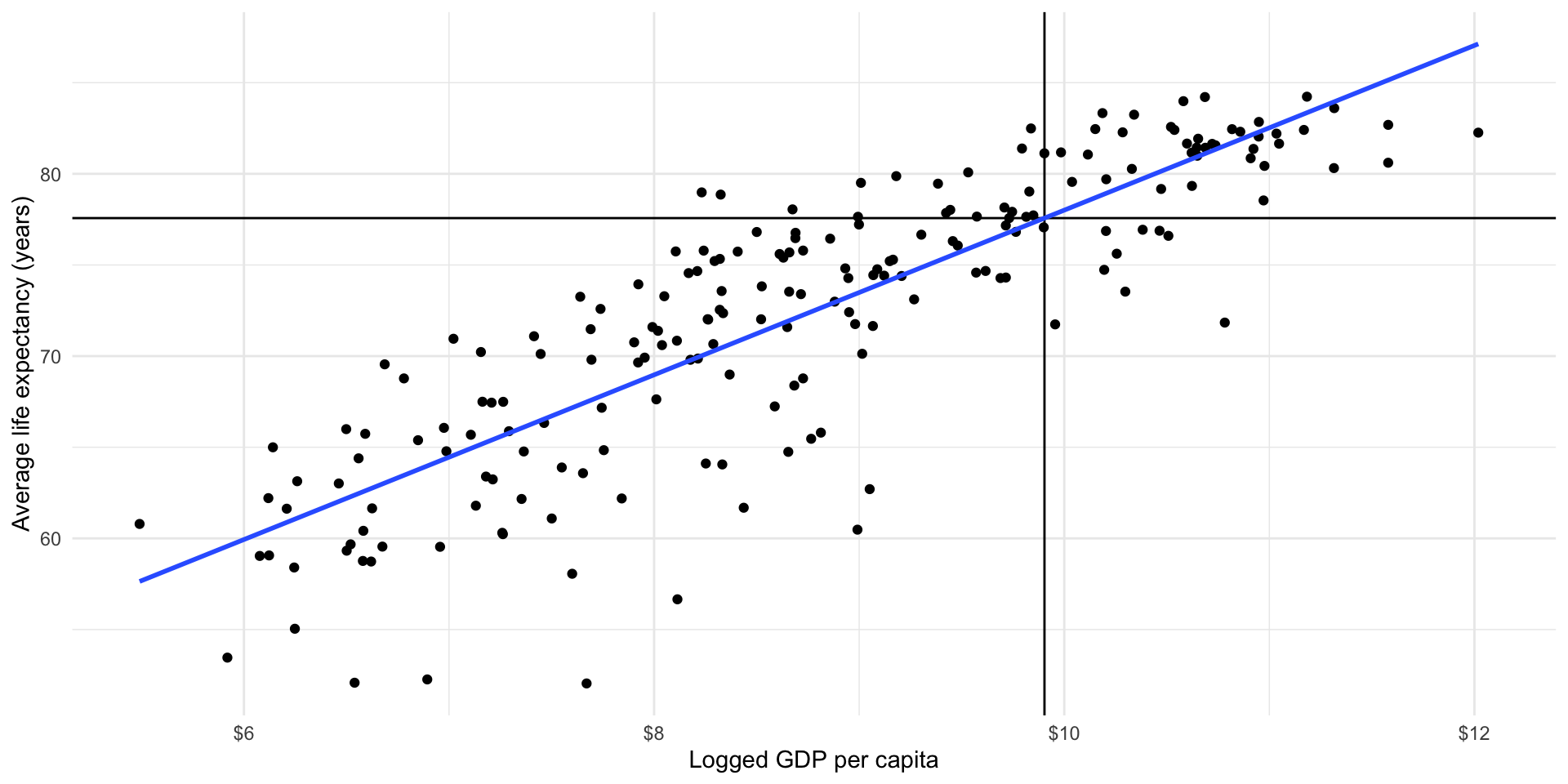
The world is a complicated and messy place. There are many countries that have a GDP per capita of around $20,000 (those dots sitting around the vertical black line). They have a wide range of average life expectancy: look at their various placement along that vertical line. Some are higher than others.
Also, there are several countries with a wide range of logged GDP per capita that have an average life expectancy of 77 years (those sitting at or around the horizontal black line). These have a wide range of logged GDP per capita: some are further to the left than others.
Our model is our best attempt at accounting for that diversity whilst still producing a useful summary of the relationship between health and wealth for those countries and all other countries with all observed values of GDP per capita.
A bit of noise (error) is expected. How much error is okay? This is a complicated question that has contested answers. Let’s start with actually measuring that error. Then we can chat about whether or not it’s small enough to allow us to be confident in our model.
Measuring error in our model
Returning to our question above, how close are our predicted values to our observed values? For example, how far from the observed average life expectancy of countries with a GDP per capita of or close to $20,000 is 77 years?
Start by working out the average life expectancy predicted by our model for the logged GDP per capita of all of our countries. We can then compare this to the average life expectancy actually observed in all these countries. We can predict values from a model using broom::augment():
augment(m)# A tibble: 210 × 9
.rownames life_exp log_gdp_per_cap .fitted .resid .hat .sigma .cooksd
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 75.5 10.2 78.9 -3.32 0.00914 4.11 0.00305
2 2 62.6 6.26 60.9 1.79 0.0190 4.11 0.00187
3 3 61.6 7.50 66.5 -4.88 0.00849 4.10 0.00611
4 4 78.6 8.34 70.3 8.34 0.00525 4.07 0.0109
5 5 84.5 10.6 80.6 3.90 0.0118 4.11 0.00545
6 6 82.2 10.6 80.7 1.47 0.0120 4.11 0.000793
7 7 76.1 9.45 75.4 0.744 0.00567 4.12 0.0000940
8 8 74.9 8.17 69.5 5.33 0.00565 4.10 0.00482
9 9 72.6 9.46 75.4 -2.77 0.00570 4.11 0.00131
10 10 77.0 9.71 76.6 0.401 0.00657 4.12 0.0000318
# ℹ 200 more rows
# ℹ 1 more variable: .std.resid <dbl>This function is simply fitting our model (\(life Exp_x = 32.9 + 4.5 * logGdpPerCap_x\)) to each country’s logged GDP per capita. You can confirm this by running the model yourself:
gapminder_df |>
transmute(
country,
log_gdp_per_cap,
.fitted = beta_0 + beta_1*log_gdp_per_cap
)# A tibble: 217 × 3
country log_gdp_per_cap .fitted
<chr> <dbl> <dbl>
1 Aruba 10.2 78.9
2 Afghanistan 6.26 60.9
3 Angola 7.50 66.5
4 Albania 8.34 70.3
5 Andorra 10.6 80.6
6 United Arab Emirates 10.6 80.7
7 Argentina 9.45 75.4
8 Armenia 8.17 69.5
9 American Samoa 9.46 75.4
10 Antigua and Barbuda 9.71 76.6
# ℹ 207 more rowsHow did the model do? What is the difference between what it predicted and the country’s observed average life expectancy? Compare .fitted (the predicted average life expectancy) to life_exp (the actual observed average life expectancy).
m_eval <- augment(m) |>
transmute(
life_exp,
.fitted,
diff = life_exp - .fitted
)
m_eval# A tibble: 210 × 3
life_exp .fitted diff
<dbl> <dbl> <dbl>
1 75.5 78.9 -3.32
2 62.6 60.9 1.79
3 61.6 66.5 -4.88
4 78.6 70.3 8.34
5 84.5 80.6 3.90
6 82.2 80.7 1.47
7 76.1 75.4 0.744
8 74.9 69.5 5.33
9 72.6 75.4 -2.77
10 77.0 76.6 0.401
# ℹ 200 more rowsNote that broom::augment() already did this calculation and stored it in the .resid variable. The formal term for the difference between the predicted and observed values is the residual.
augment(m) |>
select(life_exp, .fitted, .resid)# A tibble: 210 × 3
life_exp .fitted .resid
<dbl> <dbl> <dbl>
1 75.5 78.9 -3.32
2 62.6 60.9 1.79
3 61.6 66.5 -4.88
4 78.6 70.3 8.34
5 84.5 80.6 3.90
6 82.2 80.7 1.47
7 76.1 75.4 0.744
8 74.9 69.5 5.33
9 72.6 75.4 -2.77
10 77.0 76.6 0.401
# ℹ 200 more rowsOkay, so there are some differences. Let’s look at those differences a bit more closely:
ggplot(augment(m), aes(x = .resid)) +
geom_density() +
geom_vline(xintercept = 0) +
theme_minimal()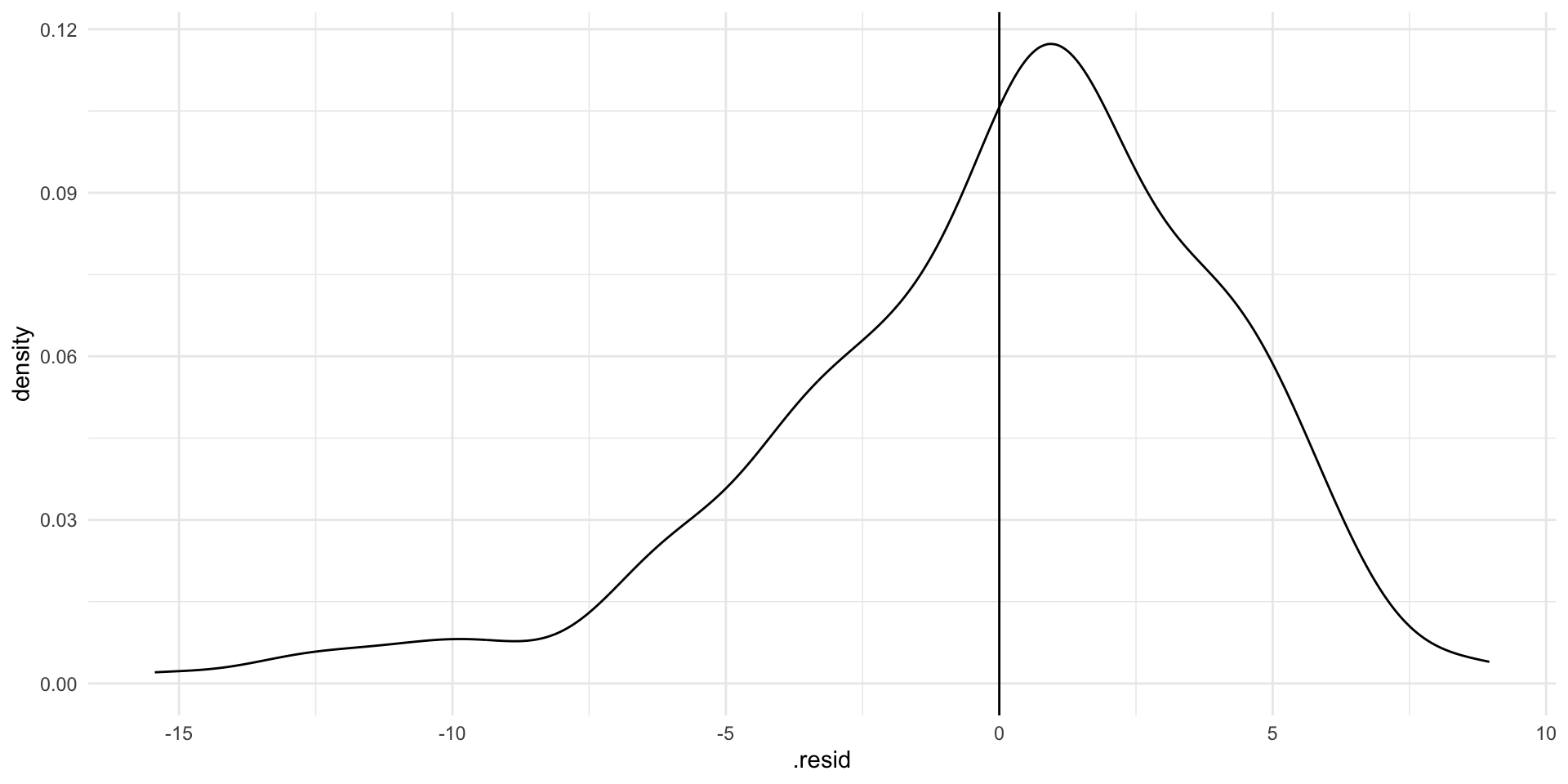
If our model perfectly predicted each country’s life expectancy, we would see no difference between the predicted and observed values. There would just be a very tall straight line at 0 on the graph above.
Our model hasn’t predicted life expectancy perfectly. Whilst most predictions are within a couple of years of the country’s true life expectancy, there are some that are very different (up to 10 or 15 years!). Where the model has got it wrong, it has tended to overestimate life expectancy (note that the peak of the density curve sits above 0).
Can you see for which points these large differences exist?
ggplot(gapminder_df, aes(x = log_gdp_per_cap, y = life_exp)) +
geom_point() +
geom_smooth(method = "lm", se = F) +
theme_minimal() +
labs(x = "Logged GDP per capita",
y = "Average life expectancy (years)") +
scale_x_continuous(labels = label_dollar())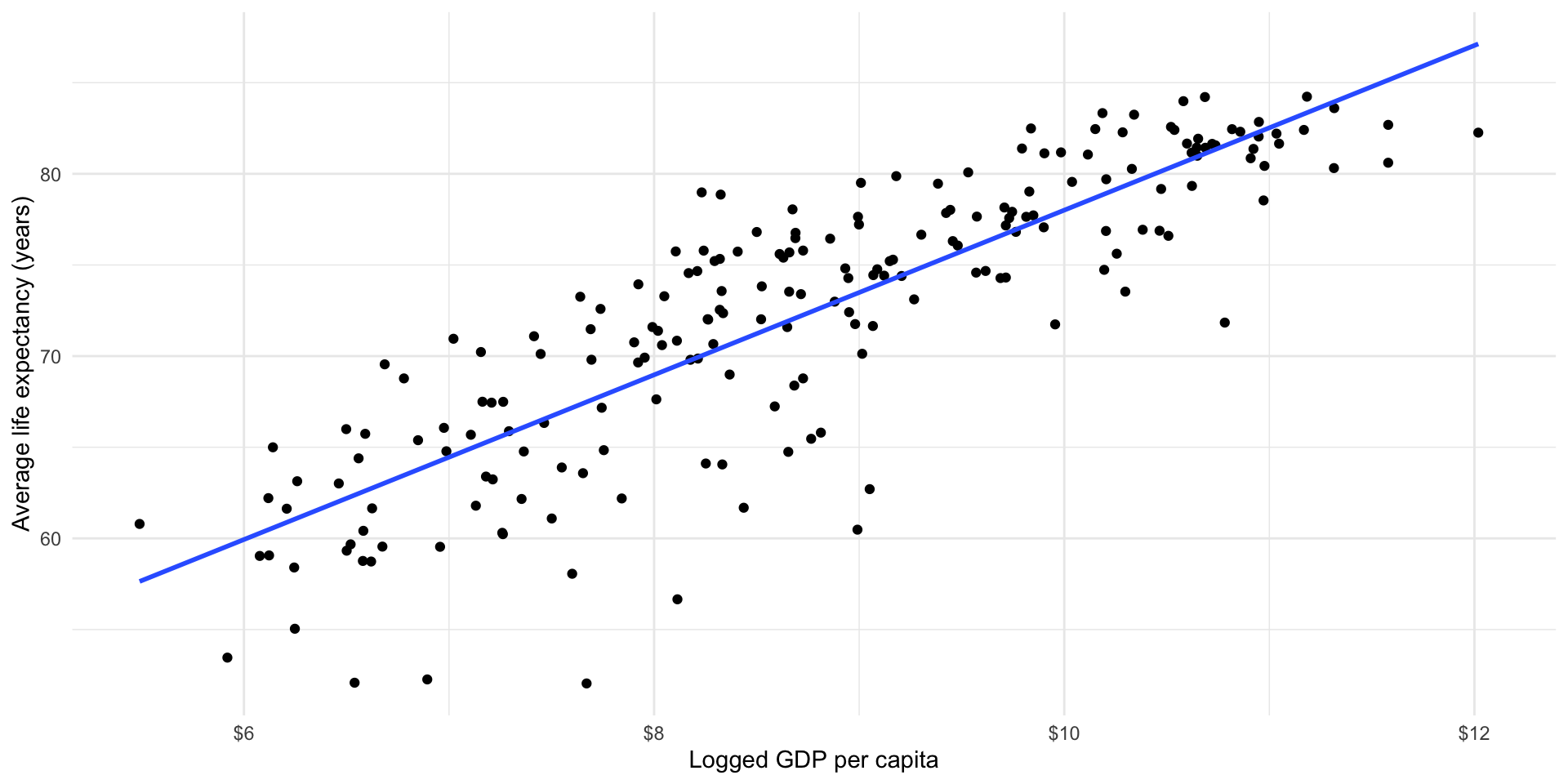
What is causing these differences? A lot of your work as a political scientist is trying to answer this very question!
(Random) error
The world is a messy and complicated place. Things often vary in random ways. That’s okay! It means that your observational data are going to move in funny and random ways. That’s okay too! As long as your model includes all of the systematic drivers of the thing you are interested in measuring (such as average life expectancy), we can accept a bit of random error.
In fact, we have already accounted for this. Remember that error term:
\[ life Exp_x = \beta_0 + \beta_1 logGdpPerCap_x + \epsilon \]
We run into issues when there are non-random things bundled up into the difference between what our model predicts and what we actually observe. We will discuss this more in later classes.
A model-wide value for error
We often want to understand how the model has performed as a whole, rather than how well it predicts each individual observed data point. There are many different ways we can do this.
Sum of squared residuals (deviance)
The sum of squared residuals measures the total error in our model. Formally:
\[ \Sigma(y_i - \hat{y_i})^2 \]
Where \(y_i\) is each observed value (the country’s actual average life expectancy) and \(\hat{y_i}\) is each predicted value (the model’s estimate of country’s average life expectancy).
We just add those all up to get a single measure of the model’s overall performance.
Note
Remember that we tend to square things when we don’t care about the direction. We don’t care that the predicted value is less or more than the observed value, just about how far they are from each other.
We can do this ourselves:
augment(m) |>
summarise(sum(.resid^2))# A tibble: 1 × 1
`sum(.resid^2)`
<dbl>
1 3507.Or we can use broom::glance():
glance(m)# A tibble: 1 × 12
r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.729 0.728 4.11 559. 6.94e-61 1 -594. 1193. 1203.
# ℹ 3 more variables: deviance <dbl>, df.residual <int>, nobs <int>glance(m) |>
select(deviance)# A tibble: 1 × 1
deviance
<dbl>
1 3507.
Tip
Where broom::tidy() gives us information about the coefficients of our model, broom::glance() gives us information on the overall model performance.
This is useful, but it is influenced by the units by which we measure our variables. If one model includes something like GDP which is measured in terms of billions of dollars, we will get a very large sum of squared residuals. If another model includes something like percentage of as state’s citizens who will vote for Donald Trump, we will get a relatively small sum of squared residuals. What if we want to compare model performance in a meaningful way?
\(R^2\)
The \(R^2\) value measures the amount of variation in the dependent variable that is explained by the independent variable. In our example, it measures how much the changes in countries’ average life expectancy is explained by the changes in their (logged) GDP per capita.
\[ R^2 = 1 - \frac{Unexplained\ variation}{Total\ variation} \]
The \(R^2\) value is useful because it does not reflect the units of measurement used in our variables. Therefore, we can compare how well different models perform.
The \(R^2\) value has three component parts.
Total Sum of Squares (TSS)
TSS measures the squared sum of the differences between all predicted values of the dependent variable and the mean of the dependent variable.
Explained Sum of Squares (ESS)
ESS measures the sum of the squares of the deviations of the predicted values from the mean value of the dependent variable.
Residual Sum of Squares (RSS)
RSS measures the difference between the TSS and ESS. In other words, the error not explained by the model.
Formally, the \(R^2\) value is:
\[ R^2 = 1 - \frac{RSS}{TSS} = 1 - \frac{\Sigma(y_i - \hat{y_i})^2}{\Sigma(y_i - \hat{y})^2} \]
Or:
\[ R^2 = \frac{ESS}{TSS} = \frac{\Sigma(\hat{y}_i - \bar{y})^2}{\Sigma(y_i - \bar{y})^2} \]
Our model’s \(R^2\) can be accessed using broom::glance():
glance(m) |>
select(r.squared)# A tibble: 1 × 1
r.squared
<dbl>
1 0.729An \(R^2\) of 1 means that all of the change in the dependent variable are completely explained by changes in the independent variable. Here, it would mean that all changes to a country’s average life expectancy are explained through changes to the country’s logged GDP per capita.
According to our model, 72.9% of changes in a country’s average life expectancy are explained through changes to the country’s logged GDP per capita.
Modelling relationships among categorical variables
Sometimes we want to know whether our outcome of interest changes based on the category in which it sits. For example, do levels of support for abortion access differ between Democrats, Republicans, and Independents? Do the number of women elected to parliament change based on whether or not the country has a formal quota? Do the number of civilians targeted in war change based on whether the war is intra- or inter-state?
Let’s return to the American National Election Survey we first explored last week. We will focus on that first question: do levels of support for abortion access differ between Democrats, Republicans, and Independents?
We can access the 2012 survey through R using the poliscidata package:
poliscidata::nesCross tabs
A simple cross tab can provide a nice summary of differences in your outcome of interest across your categories.
For example, let’s look at differences in the number of individuals who identified as Democrat, Republican, or Independent who do not support access to abortions, support access with some conditions, with more conditions, or always.
We can use modelsummary::datasummary_crosstab() to produce a nicely formatted cross tab of our variables:
datasummary_crosstab(abort4 ~ pid_3, data = nes)| abort4 | Dem | Ind | Rep | All | |
|---|---|---|---|---|---|
| Never | N | 187 | 229 | 252 | 672 |
| % row | 27.8 | 34.1 | 37.5 | 100.0 | |
| Some conds | N | 499 | 583 | 519 | 1607 |
| % row | 31.1 | 36.3 | 32.3 | 100.0 | |
| More conds | N | 332 | 337 | 227 | 898 |
| % row | 37.0 | 37.5 | 25.3 | 100.0 | |
| Always | N | 1325 | 964 | 381 | 2680 |
| % row | 49.4 | 36.0 | 14.2 | 100.0 | |
| All | N | 2358 | 2149 | 1385 | 5916 |
| % row | 39.9 | 36.3 | 23.4 | 100.0 |
We can also visualise this:
nes |>
count(pid_3, abort4) |>
drop_na(pid_3) |>
ggplot(aes(x = n, y = pid_3, fill = abort4)) +
geom_bar(position = "dodge", stat = "identity") +
theme_minimal() +
labs(x = "N",
y = NULL,
fill = "Level of support") +
scale_fill_manual(values = c("#EDE5CF","#E0C2A2","#D39C83","#C1766F"))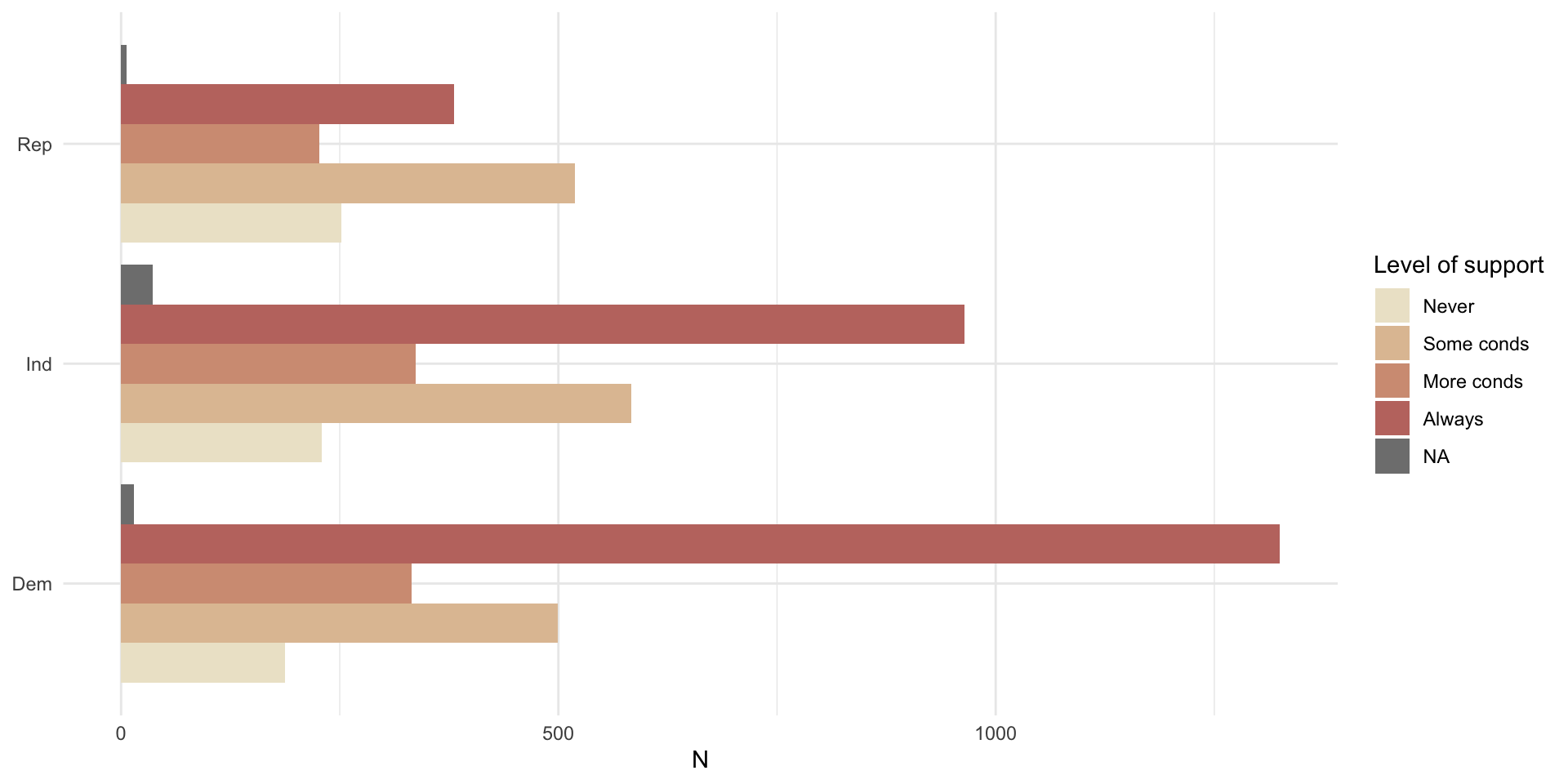
Or this:
nes |>
count(pid_3, abort4) |>
drop_na(pid_3) |>
ggplot(aes(x = n, y = abort4, fill = pid_3)) +
geom_bar(position = "dodge", stat = "identity") +
theme_minimal() +
labs(x = "N",
y = NULL,
fill = "Party") +
scale_fill_manual(values = c("#1375B7","lightgrey","#C93135"))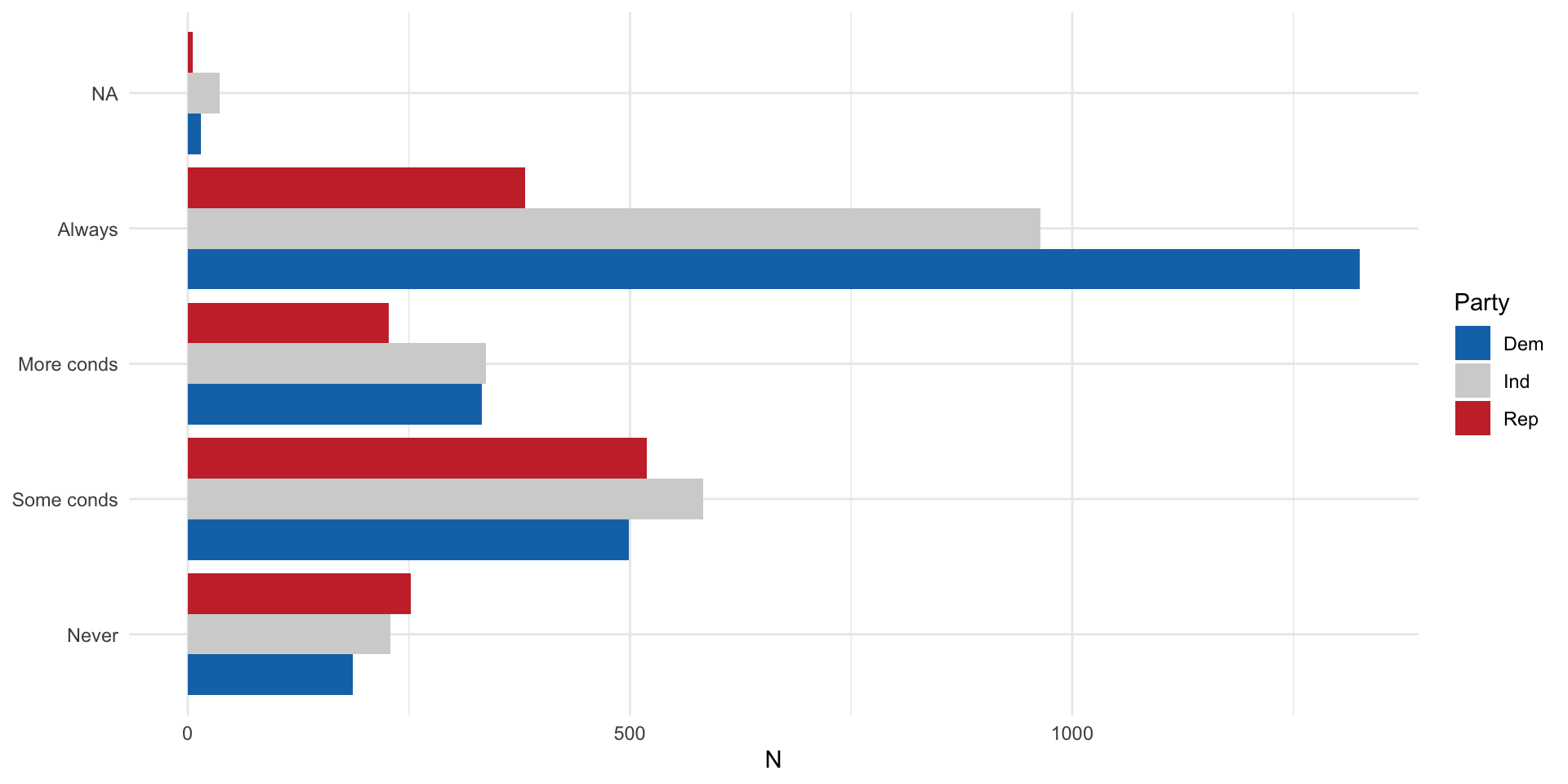
Mean comparison table
We can use mean comparison tables to, well, compare means (in a table). Let’s compare the average response to the feeling thermometer (scale from 0 to 100) for the Republican party across parties:
nes |>
group_by(pid_3) |>
summarise(
mean = mean(ft_rep, na.rm = T),
sd = sd(ft_rep, na.rm = T),
freq = n()
)# A tibble: 4 × 4
pid_3 mean sd freq
<fct> <dbl> <dbl> <int>
1 Dem 24.5 21.8 2358
2 Ind 43.0 23.1 2149
3 Rep 70.3 18.3 1385
4 <NA> 50 14.7 24Are these counts or averages meaningfully different from one another? We need some additional tools to answer that question. We will discuss those in the coming weeks.
Looking at the whole distribution
We can also visualize the whole distribution of a continuous variable of interest within our categories.
nes |>
drop_na(pid_3) |>
ggplot(aes(x = ft_rep, fill = pid_3)) +
geom_density(alpha = 0.5) +
theme_minimal() +
scale_fill_manual(values = c("#1375B7","lightgrey","#C93135")) +
labs(x = "Feeling thermometer",
y = "Density",
fill = "Party")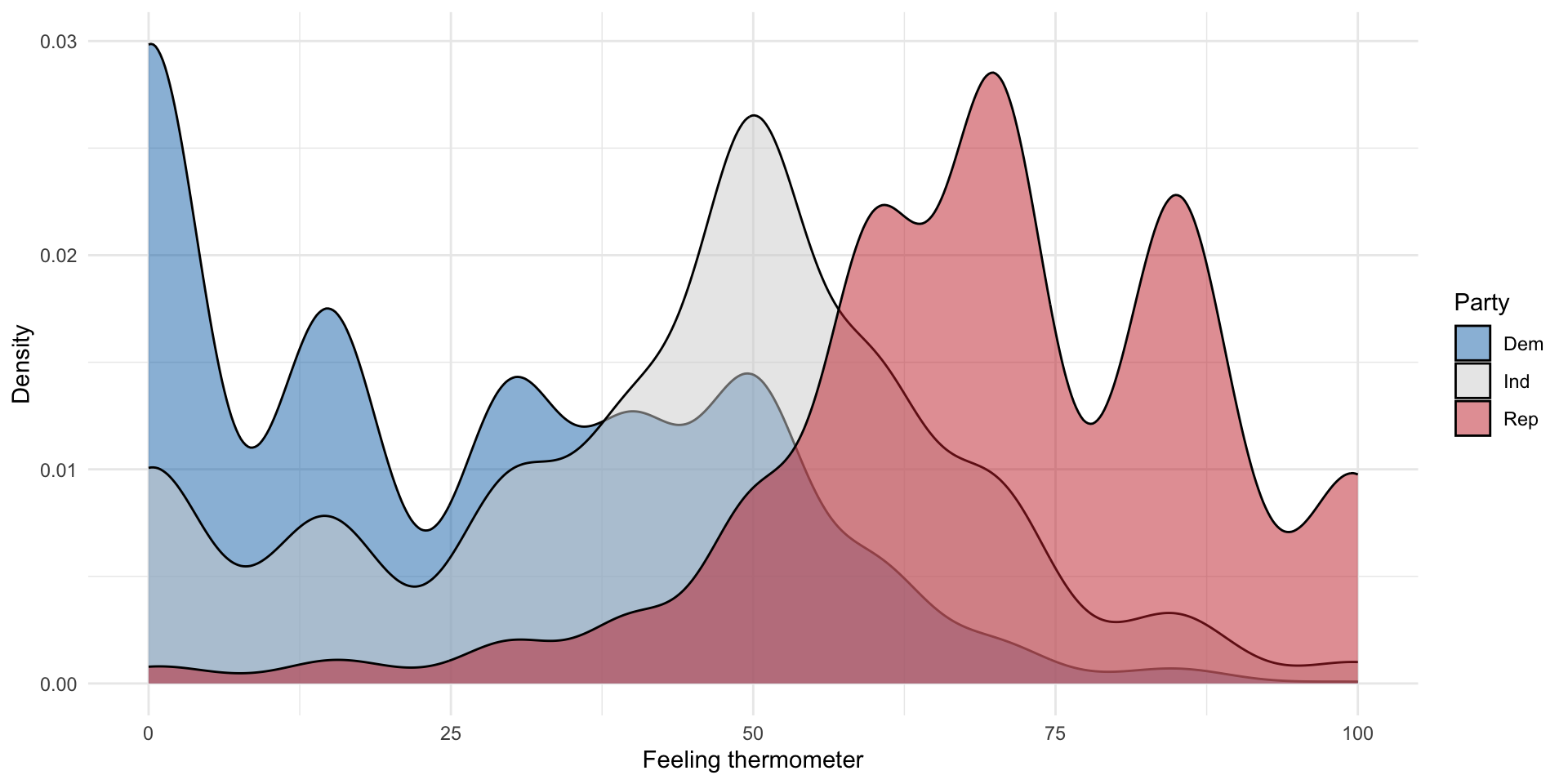
As expected, Democrats appear to respond least favourably to the Republican Party, followed by Independents, and Republicans. This is demonstrated by both the mean comparison table and density plots.